我将设计一个MLP,它是全连接的,有2个隐藏层和1个输出层。如果我使用批量或小批量梯度下降,我可以得到一个不错的学习曲线。
但是,当执行随机梯度下降(紫色)时,我得到了一条直线,如下图所示: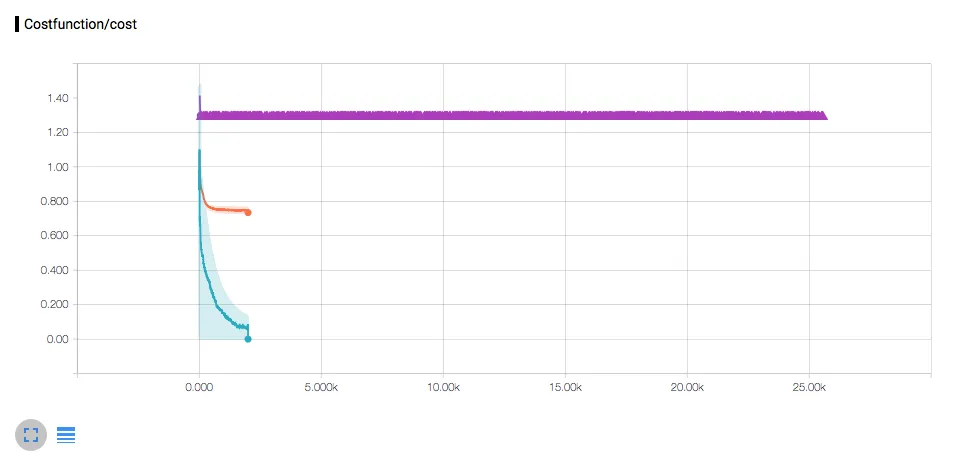 我做错了什么?
我做错了什么?
在我的理解中,如果我每个训练步骤只提供一个训练/学习示例,那么我就是使用Tensorflow进行随机梯度下降:
但是,当执行随机梯度下降(紫色)时,我得到了一条直线,如下图所示:
我做错了什么?在我的理解中,如果我每个训练步骤只提供一个训练/学习示例,那么我就是使用Tensorflow进行随机梯度下降:
X = tf.placeholder("float", [None, amountInput],name="Input")
Y = tf.placeholder("float", [None, amountOutput],name="TeachingInput")
...
m, i = sess.run([merged, train_op], feed_dict={X:[input],Y:[label]})
输入是一个由10个组成的向量,标签是一个由20个组成的向量。
为了测试,我运行了1000次迭代,每次迭代都包含50个准备好的训练/学习示例之一。我预期会出现过拟合的神经网络。但是,正如你所看到的,它并没有学习。
由于神经网络将在在线学习环境中执行,小批量梯度下降或批量梯度下降不是一个选项。
感谢任何提示。
y = b0 + b1 * x函数进行了测试。 我可以输出每个参数相对于梯度总和的梯度和. 在每个步骤中 delta(b0) = learning_rate * grad_sum(b0)。 批处理中的值越多,则总和越高。这就是为什么在批处理模式下,每个步骤中获取更高的参数变化。 实际上,在一个步骤中,通过馈送一批数据,参数变化等于对这批数据进行拆分并逐个馈送时的变化总和。 如果需要,我可以共享我的输出结果。 请帮助理解此问题。 - noname7619