我试图使用MNIST手写数字数据集(包括60,000个训练样本)训练前馈神经网络。
每次迭代中,我会对所有训练样本执行反向传播,在每个时期为每个样本执行一次。但运行时间当然太长了。
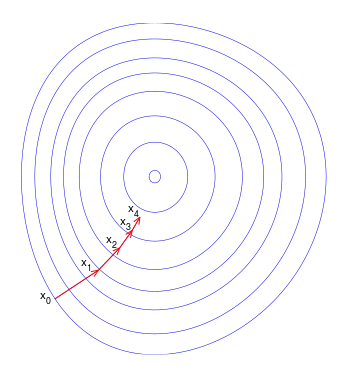
- 我运行的算法是梯度下降吗?
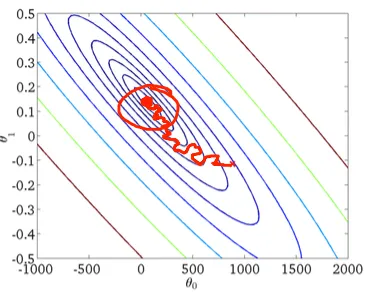
我读到过,对于大型数据集,使用随机梯度下降可以显著提高运行时间。
- 为了使用随机梯度下降,我应该做什么?我只需要随机选择训练样本,在每个随机选择的样本上执行反向传播,而不是我当前使用的时期吗?
我试图使用MNIST手写数字数据集(包括60,000个训练样本)训练前馈神经网络。
每次迭代中,我会对所有训练样本执行反向传播,在每个时期为每个样本执行一次。但运行时间当然太长了。
我读到过,对于大型数据集,使用随机梯度下降可以显著提高运行时间。
error = 0
for sample in data:
prediction = neural_network.predict(sample)
sample_error = evaluate_error(prediction, sample["label"]) # may be as simple as
# module(prediction - sample["label"])
error += sample_error
neural_network.backpropagate_and_update(error)
randomly shuffle samples in the training set
for one or more epochs, or until approx. cost minimum is reached:
for training sample i:
compute gradients and perform weight updates
B)
for one or more epochs, or until approx. cost minimum is reached:
randomly shuffle samples in the training set
for training sample i:
compute gradients and perform weight updates
C)
for iterations t, or until approx. cost minimum is reached:
draw random sample from the training set
compute gradients and perform weight updates