我正在修改Brieman的随机森林程序(我不懂C/C++),所以我已经在R中从头编写了自己的RF变体。我的过程与标准过程的区别基本上只在于如何计算分割点和终端节点中的值——一旦我有了一个森林中的树,它可以被认为与典型RF算法中的树非常相似。
我的问题是它的预测速度很慢,我很难想到使它更快的方法。
测试树对象链接在这里,一些测试数据链接在这里。您可以直接下载,或者如果您安装了repmis,则可以在下面加载。它们被称为testtree和sampx。
library(repmis)
testtree <- source_DropboxData(file = "testtree", key = "sfbmojc394cnae8")
sampx <- source_DropboxData(file = "sampx", key = "r9imf317hpflpsx")
编辑:不知何故我仍然没有真正学会如何使用Github。 我已将所需文件上传到此处的存储库中 - 很抱歉我目前无法弄清如何获得永久链接...
它看起来像这样(使用我编写的绘图函数):
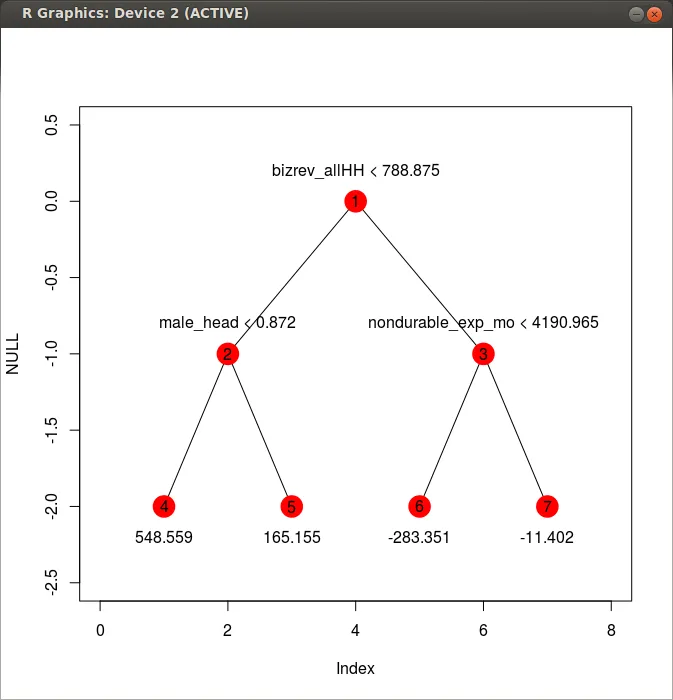
这是关于该对象结构的一些信息:
1> summary(testtree)
Length Class Mode
nodes 7 -none- list
minsplit 1 -none- numeric
X 29 data.frame list
y 6719 -none- numeric
weights 6719 -none- numeric
oob 2158 -none- numeric
1> summary(testtree$nodes)
Length Class Mode
[1,] 4 -none- list
[2,] 8 -none- list
[3,] 8 -none- list
[4,] 7 -none- list
[5,] 7 -none- list
[6,] 7 -none- list
[7,] 7 -none- list
1> summary(testtree$nodes[[1]])
Length Class Mode
y 6719 -none- numeric
output 1 -none- numeric
Terminal 1 -none- logical
children 2 -none- numeric
1> testtree$nodes[[1]][2:4]
$output
[1] 40.66925
$Terminal
[1] FALSE
$children
[1] 2 3
1> summary(testtree$nodes[[2]])
Length Class Mode
y 2182 -none- numeric
parent 1 -none- numeric
splitvar 1 -none- character
splitpoint 1 -none- numeric
handedness 1 -none- character
children 2 -none- numeric
output 1 -none- numeric
Terminal 1 -none- logical
1> testtree$nodes[[2]][2:8]
$parent
[1] 1
$splitvar
[1] "bizrev_allHH"
$splitpoint
25%
788.875
$handedness
[1] "Left"
$children
[1] 4 5
$output
[1] 287.0085
$Terminal
[1] FALSE
output是该节点的返回值 -- 我希望其他部分都可以自解释。
我编写的预测函数能够正常工作,但速度太慢了。基本上它会“逐个观察地向下遍历树”:
predict.NT = function(tree.obj, newdata=NULL){
if (is.null(newdata)){X = tree.obj$X} else {X = newdata}
tree = tree.obj$nodes
if (length(tree)==1){#Return the mean for a stump
return(rep(tree[[1]]$output,length(X)))
}
pred = apply(X = newdata, 1, godowntree, nn=1, tree=tree)
return(pred)
}
godowntree = function(x, tree, nn = 1){
while (tree[[nn]]$Terminal == FALSE){
fb = tree[[nn]]$children[1]
sv = tree[[fb]]$splitvar
sp = tree[[fb]]$splitpoint
if (class(sp)=='factor'){
if (as.character(x[names(x) == sv]) == sp){
nn<-fb
} else{
nn<-fb+1
}
} else {
if (as.character(x[names(x) == sv]) < sp){
nn<-fb
} else{
nn<-fb+1
}
}
}
return(tree[[nn]]$output)
}
问题在于它非常慢(当你考虑到非样本树更大,并且我需要做这么多次时),即使是简单的一棵树也是如此:
library(microbenchmark)
microbenchmark(predict.NT(testtree,sampx))
Unit: milliseconds
expr min lq mean median uq
predict.NT(testtree, sampx) 16.19845 16.36351 17.37022 16.54396 17.07274
max neval
40.4691 100
今天有人给了我一个想法,我可以编写一种函数工厂类型的函数(即:生成闭包的函数,这是我刚学习的),将我的树拆分为一堆嵌套的if / else语句。然后我可以通过它发送数据,这可能比一遍又一遍地从树中提取数据更快。我还没有编写生成函数的函数,但我手动编写了我会得到的输出类型,并进行了测试:
predictif = function(x){
if (x[names(x) == 'bizrev_allHH'] < 788.875){
if (x[names(x) == 'male_head'] <.872){
return(548)
} else {
return(165)
}
} else {
if (x[names(x) == 'nondurable_exp_mo'] < 4190.965){
return(-283)
}else{
return(-11.4)
}
}
}
predictif.NT = function(tree.obj, newdata=NULL){
if (is.null(newdata)){X = tree.obj$X} else {X = newdata}
tree = tree.obj$nodes
if (length(tree)==1){#Return the mean for a stump
return(rep(tree[[1]]$output,length(X)))
}
pred = apply(X = newdata, 1, predictif)
return(pred)
}
microbenchmark(predictif.NT(testtree,sampx))
Unit: milliseconds
expr min lq mean median uq
predictif.CT(testtree, sampx) 12.77701 12.97551 14.21417 13.18939 13.67667
max neval
30.48373 100
速度稍微快了一点,但并不明显!
如果您有任何加速的想法,我将非常感激!或者,如果答案是“您真的不能在不将其转换为C/C++的情况下获得更快的速度”,那也是有价值的信息(特别是如果您能给我一些关于为什么会这样的信息)。
虽然我肯定会欣赏R中的答案,但伪代码的答案也会非常有帮助。
谢谢!
dput(testtree)的结果? - David Robinsondput(testree),结果数据太大了。让我想一想更好的链接数据的方法... - generic_usertransform(sampx, n1 = bizrev_allHH < 788.875, n2 = male_head < .872)等等。基于此,它可以变得非常快速(无需使用C或C++),并且经过一些工作可以使其适用于任何决策树。 - David Robinson