我正在使用 R 对包含以下数据结构的数据帧“d”进行分类:
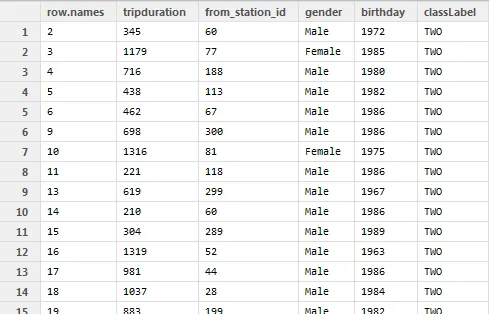 数据有 576666 行,“classLabel”列具有 3 级因子:ONE、TWO、THREE。
数据有 576666 行,“classLabel”列具有 3 级因子:ONE、TWO、THREE。
我正在使用 rpart 制作决策树。
数据有 576666 行,“classLabel”列具有 3 级因子:ONE、TWO、THREE。我正在使用 rpart 制作决策树。
fitTree = rpart(d$classLabel ~ d$tripduration + d$from_station_id + d$gender + d$birthday)
我希望能够预测newdata中的"classLabel"值:
newdata = data.frame( tripduration=c(345,244,543,311),
from_station_id=c(60,28,100,56),
gender=c("Male","Female","Male","Male"),
birthday=c(1972,1955,1964,1967) )
p <- predict(fitTree, newdata)
newdata 可能的 "classLabel" 三个值的概率。但是我得到的 p 结果是一个包含 576666 行的数据框,就像下面这样:
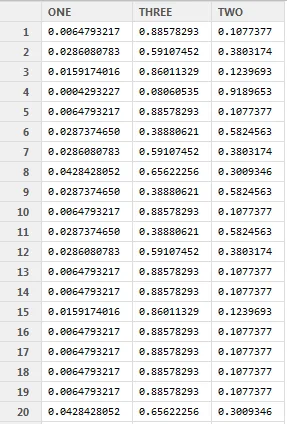
predict 函数时还会收到以下警告:Warning message:
'newdata' had 4 rows but variables found have 576666 rows
我到底做错了什么?!
$,而是使用rpart(classLabel ~ tripduration + from_station_id + gender + birthday, data=d),否则变量将与数据框"d"绑定,不能在新数据框内解析。未来,请确保包含一个可重现的示例(https://dev59.com/eG025IYBdhLWcg3whGSx)和输入样本数据,以便我们能够获得与你相同的错误(数据的图像不算)。 - MrFlick