我正在处理一些Matlab代码,用于处理大型(但不是巨大的)数据集:10,000个784元素向量(非稀疏),并计算存储在10,000 x 10稀疏矩阵中的信息。为了让代码正常工作,我使用循环处理了其中一些较棘手的部分,对这10k个项目进行了循环处理,并对稀疏矩阵中的10个项目进行了清理。
我的处理过程最初需要73次迭代(因此大约循环了730k次),并且运行时间约为120秒。这还不错,但由于这是Matlab,所以我试图将其向量化以加快速度。
最终,我有了一个完全向量化的解决方案,它得到了与初始解决方案相同的答案(因此它是正确的,或者至少与我的初始解决方案一样正确),但运行时间为274秒,几乎慢了一半!
这是我第一次遇到向量化后比迭代更慢的Matlab代码。是否有任何经验法则或最佳实践可用于确定何时可能/可能出现这种情况?
我很想分享代码以获得反馈,但它是当前开放的学校任务,所以我现在真的不能分享。如果它最终成为那些“哇,那很奇怪,你可能做错了什么”的事情之一,我可能会在一两周内重新审视它,看看我的向量化是否有误。
我的处理过程最初需要73次迭代(因此大约循环了730k次),并且运行时间约为120秒。这还不错,但由于这是Matlab,所以我试图将其向量化以加快速度。
最终,我有了一个完全向量化的解决方案,它得到了与初始解决方案相同的答案(因此它是正确的,或者至少与我的初始解决方案一样正确),但运行时间为274秒,几乎慢了一半!
这是我第一次遇到向量化后比迭代更慢的Matlab代码。是否有任何经验法则或最佳实践可用于确定何时可能/可能出现这种情况?
我很想分享代码以获得反馈,但它是当前开放的学校任务,所以我现在真的不能分享。如果它最终成为那些“哇,那很奇怪,你可能做错了什么”的事情之一,我可能会在一两周内重新审视它,看看我的向量化是否有误。
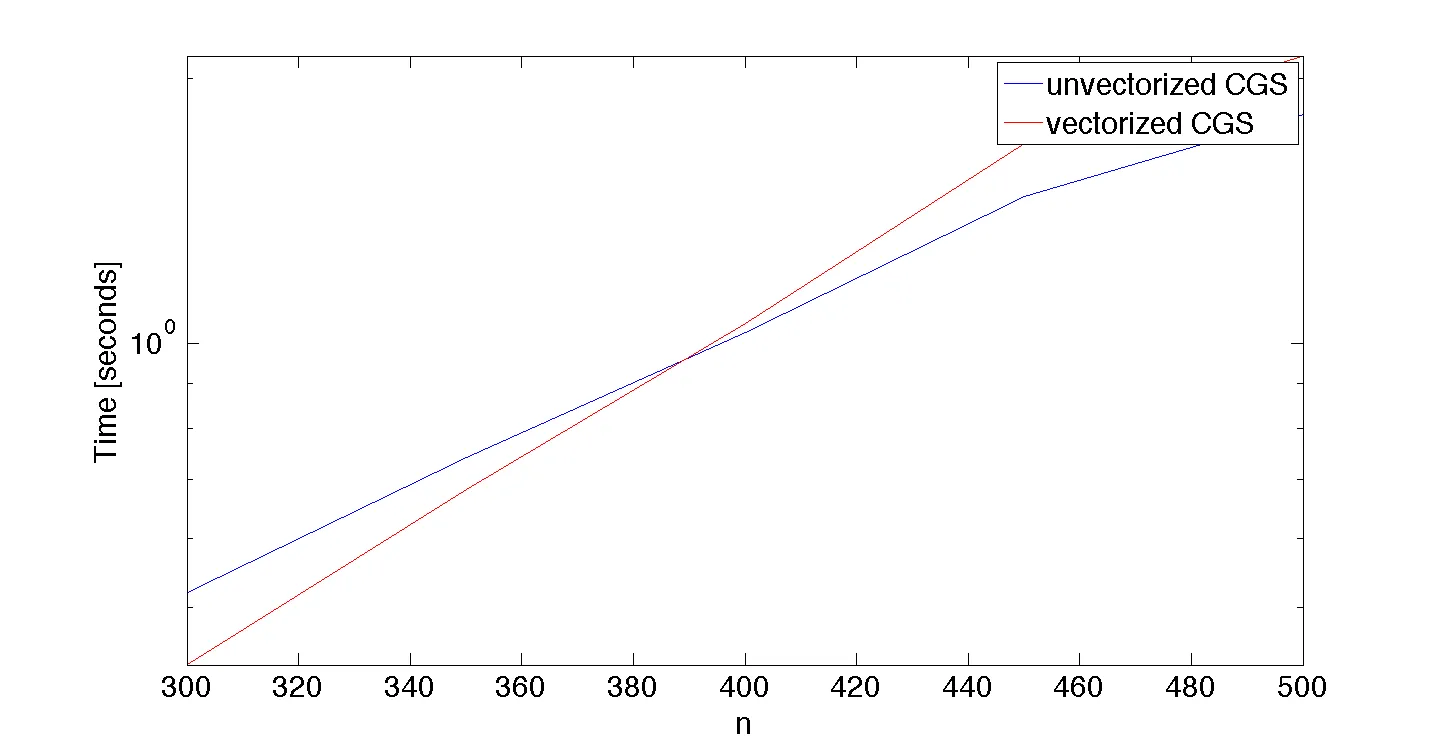 以下是两个实现和基准测试脚本:
以下是两个实现和基准测试脚本: