我正在尝试做与this相反的事情:给定一张二维图像(连续)强度,生成一组不规则间隔的积累点,即在二维地图上不规则覆盖的点,在强度高的区域彼此更接近(但不重叠!)。
我的第一次尝试是“加权”k-means。由于没有找到可行的加权k-means实现方式,我引入权重的方法是重复具有高强度的点。这是我的代码:
我的第一次尝试是“加权”k-means。由于没有找到可行的加权k-means实现方式,我引入权重的方法是重复具有高强度的点。这是我的代码:
import numpy as np
from sklearn.cluster import KMeans
def accumulation_points_finder(x, y, data, n_points, method, cut_value):
#computing the rms
rms = estimate_rms(data)
#structuring the data
X,Y = np.meshgrid(x, y, sparse=False)
if cut_value > 0.:
mask = data > cut_value
#applying the mask
X = X[mask]; Y = Y[mask]; data = data[mask]
_data = np.array([X, Y, data])
else:
X = X.ravel(); Y = Y.ravel(); data = data.ravel()
_data = np.array([X, Y, data])
if method=='weighted_kmeans':
res = []
for i in range(len(data)):
w = int(ceil(data[i]/rms))
res.extend([[X[i],Y[i]]]*w)
res = np.asarray(res)
#kmeans object instantiation
kmeans = KMeans(init='k-means++', n_clusters=n_points, n_init=25, n_jobs=2)
#performing kmeans clustering
kmeans.fit(res)
#returning just (x,y) positions
return kmeans.cluster_centers_
这里有两个不同的结果:1)利用所有数据像素。2)仅利用高于某个阈值(RMS)的像素。
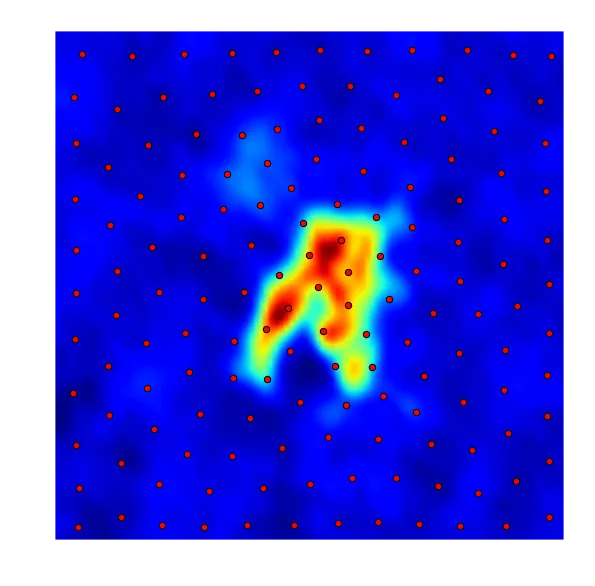
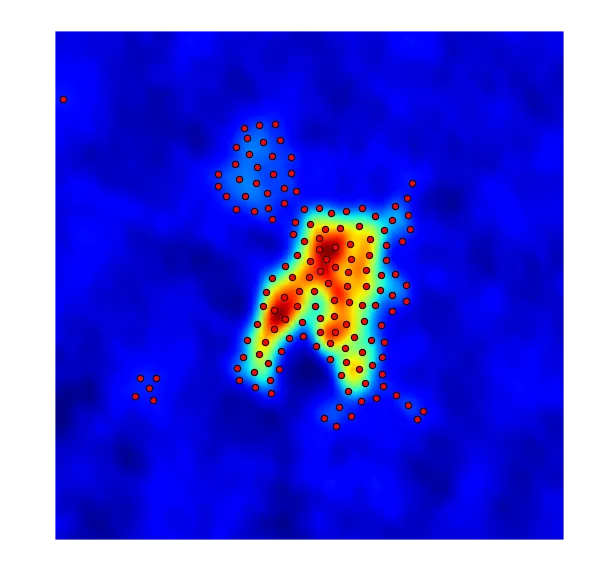
正如您所看到的,这些点似乎比集中在高强度区域更加均匀分布。
因此,我的问题是是否存在一种(如果可能是确定性的)更好的方法来计算这样的积累点。