当使用numpy计算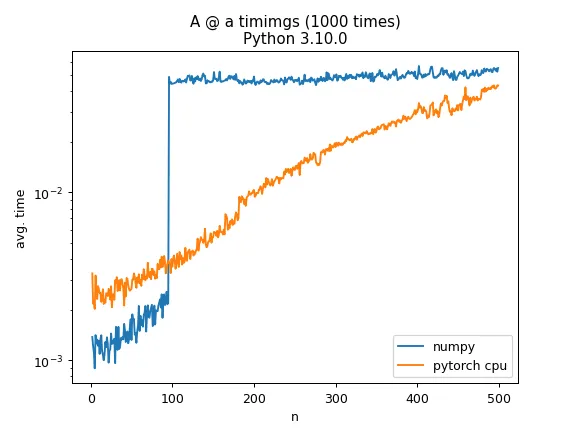 已尝试使用python3.10、3.9和3.7生成相同行为。
已尝试使用python3.10、3.9和3.7生成相同行为。
用于生成绘图的numpy部分的代码如下:
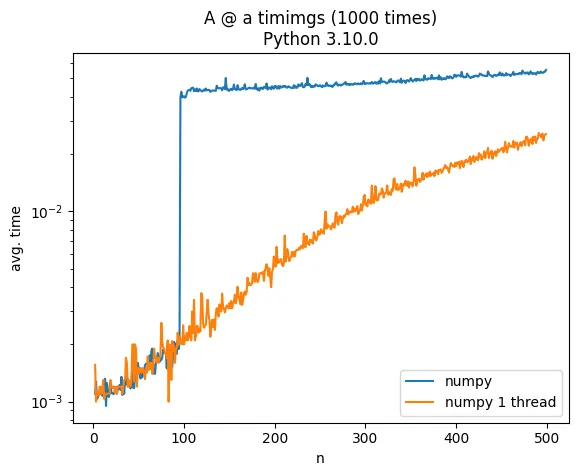
A @ a时,其中A是一个随机的N x N矩阵,a是一个具有N个随机元素的向量,在N=100时,计算时间会增加一个数量级。这是有什么特别的原因吗?相比之下,使用torch在cpu上进行相同操作的增长更为渐进。
已尝试使用python3.10、3.9和3.7生成相同行为。用于生成绘图的numpy部分的代码如下:
import numpy as np
from tqdm.notebook import tqdm
import pandas as pd
import time
import sys
def sym(A):
return .5 * (A + A.T)
results = []
for n in tqdm(range(2, 500)):
for trial_idx in range(10):
A = sym(np.random.randn(n, n))
a = np.random.randn(n)
t = time.time()
for i in range(1000):
A @ a
t = time.time() - t
results.append({
'n': n,
'time': t,
'method': 'numpy',
})
results = pd.DataFrame(results)
from matplotlib import pyplot as plt
fig, ax = plt.subplots(1, 1)
ax.semilogy(results.n.unique(), results.groupby('n').time.mean(), label="numpy")
ax.set_title(f'A @ a timimgs (1000 times)\nPython {sys.version.split(" ")[0]}')
ax.legend()
ax.set_xlabel('n')
ax.set_ylabel('avg. time')
更新
添加
import os
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
os.environ["OMP_NUM_THREADS"] = "1"
在使用 ìmport numpy 前给出一个更符合预期的输出,详情请参考此答案:https://dev59.com/WFEG5IYBdhLWcg3wHUNc#74662135