我可以使用numpy的内置功能计算自相关:
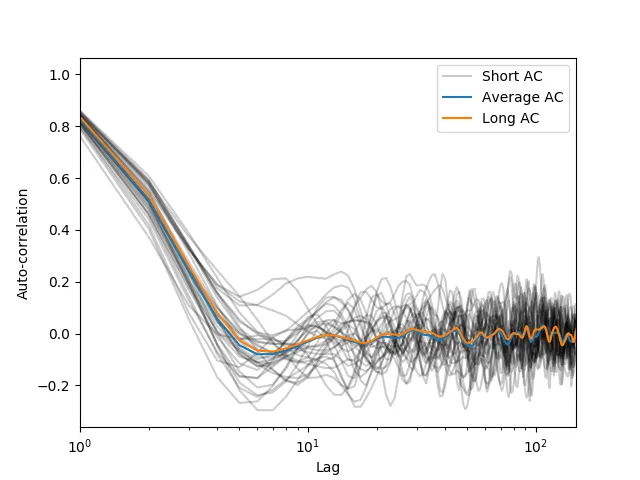
更新 这是受@kazemakase回答启发的。我尝试用一些用于生成下面图像的代码来说明我的意思。 可以看到@kazemakase是正确的,事实上AC函数自然地平均了噪声。然而,对于AC的平均处理具有更快的优势!
numpy.correlate(x,x,mode='same')
然而,所得到的相关性自然是有噪声的。我可以将数据分区,并在每个结果窗口上计算相关性,然后将它们全部平均起来以计算更干净的自相关,类似于signal.welch所做的。是否有一个方便的函数在numpy或scipy中可以做到这一点,可能比我自己计算分区并循环遍历数据得到的速度更快?更新 这是受@kazemakase回答启发的。我尝试用一些用于生成下面图像的代码来说明我的意思。 可以看到@kazemakase是正确的,事实上AC函数自然地平均了噪声。然而,对于AC的平均处理具有更快的优势!
np.correlate似乎缩放为缓慢的O(n^2),而不是我希望通过使用FFT通过循环卷积计算相关性时期望的O(nlogn)...
from statsmodels.tsa.arima_model import ARIMA
import statsmodels as sm
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(12345)
arparams = np.array([.75, -.25, 0.2, -0.15])
maparams = np.array([.65, .35])
ar = np.r_[1, -arparams] # add zero-lag and negate
ma = np.r_[1, maparams] # add zero-lag
x = sm.tsa.arima_process.arma_generate_sample(ar, ma, 10000)
def calc_rxx(x):
x = x-x.mean()
N = len(x)
Rxx = np.correlate(x,x,mode="same")[N/2::]/N
#Rxx = np.correlate(x,x,mode="same")[N/2::]/np.arange(N,N/2,-1)
return Rxx/x.var()
def avg_rxx(x,nperseg=1024):
rxx_windows = []
Nw = int(np.floor(len(x)/nperseg))
print Nw
first = True
for i in range(Nw-1):
xw = x[i*nperseg:nperseg*(i+1)]
y = calc_rxx(xw)
if i%1 == 0:
if first:
plt.semilogx(y,"k",alpha=0.2,label="Short AC")
first = False
else:
plt.semilogx(y,"k",alpha=0.2)
rxx_windows.append(y)
print np.shape(rxx_windows)
return np.mean(rxx_windows,axis=0)
plt.figure()
r_avg = avg_rxx(x,nperseg=300)
r = calc_rxx(x)
plt.semilogx(r_avg,label="Average AC")
plt.semilogx(r,label="Long AC")
plt.xlabel("Lag")
plt.ylabel("Auto-correlation")
plt.legend()
plt.xlim([0,150])
plt.show()
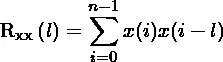
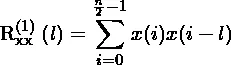
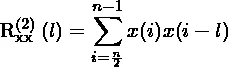
same选项。 - Dipole