我认为beetroot上面的答案更加优雅,但是我也在解决同样的问题,并且用了不同的方法到达了同样的结果。我觉得这很有趣,因为我使用了“双重融化”(口感好!)来排列x、y/p、q对。此外,它演示了tidyr::gather而不是melt。
library(tidyr)
x.df<- data.frame(Year=2001:2004,
x=runif(4,8,9),y=runif(4,8,9),
p=runif(4,3,9),q=runif(4,3,9))
x.df.melt<-gather(x.df,"item","item_val",-Year,-p,-q) %>%
group_by(item,Year) %>%
gather("comparison","comp_val",-Year,-item,-item_val) %>%
filter((item=="x" & comparison=="p")|(item=="y" & comparison=="q"))
> x.df.melt
Year item item_val comparison comp_val
<int> <chr> <dbl> <chr> <dbl>
1 2001 x 8.400538 p 5.540549
2 2002 x 8.169680 p 5.750010
3 2003 x 8.065042 p 8.821890
4 2004 x 8.311194 p 7.714197
5 2001 y 8.449290 q 5.471225
6 2002 y 8.266304 q 7.014389
7 2003 y 8.146879 q 7.298253
8 2004 y 8.960238 q 5.342702
请看下面的绘图语句。
这种方法的一个弱点(以及beetroot使用ifelse的弱点)是如果你有很多对比要进行,filter语句很快就会变得难以操作。在我的用例中,我正在比较共同基金的表现与许多基准指数。每个基金都有不同的基准。我通过一个元数据表来解决这个问题,将基金代码与其相应的基准进行配对,然后使用left/right_join。在这种情况下:
pair_data<-data.frame(item=c("x","y"),comparison=c("p","q"))
x.df.melt2<-x.df %>% gather("item","item_val",-Year) %>%
left_join(pair_data)
x.df.melt2<-x.df.melt2 %>%
select(Year,item,item_val) %>%
rename(comparison=item,comp_val=item_val) %>%
right_join(x.df.melt2,by=c("Year","comparison")) %>%
na.omit() %>%
group_by(item,Year)
ggplot(x.df.melt2,aes(Year,item_val,color="item"))+geom_line()+
geom_line(aes(y=comp_val,color="comp"))+
guides(col = guide_legend(title = NULL))+
ylab("Value")+
facet_grid(~item)
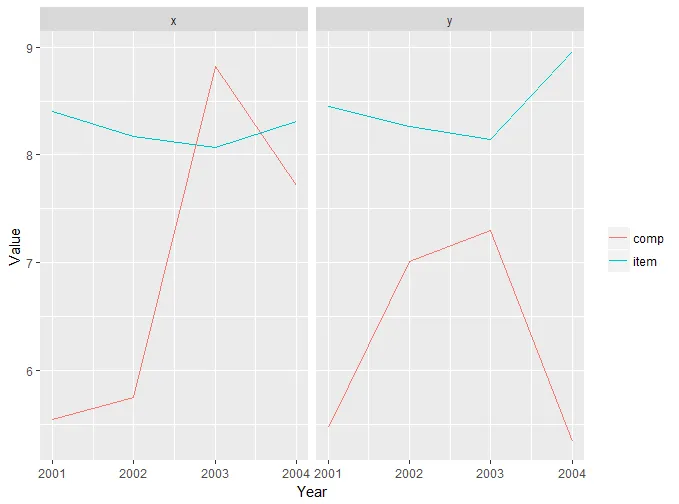
由于不需要新的分组变量,我们将参考项(item)的名称作为图中的标签。
此句话是关于it技术的内容。