我需要计算大量的3x3线性变换(例如旋转)。这是我目前所拥有的:
import numpy as np
from scipy import sparse
from numba import jit
n = 100000 # number of transformations
k = 100 # number of vectors for each transformation
A = np.random.rand(n, 3, k) # vectors
Op = np.random.rand(n, 3, 3) # operators
sOp = sparse.bsr_matrix((Op, np.arange(n), np.arange(n+1))) # same as Op but as block-diag
def dot1():
""" naive approach: many times np.dot """
return np.stack([np.dot(o, a) for o, a in zip(Op, A)])
@jit(nopython=True)
def dot2():
""" same as above, but jitted """
new = np.empty_like(A)
for i in range(Op.shape[0]):
new[i] = np.dot(Op[i], A[i])
return new
def dot3():
""" using einsum """
return np.einsum("ijk,ikl->ijl", Op, A)
def dot4():
""" using sparse block diag matrix """
return sOp.dot(A.reshape(3 * n, -1)).reshape(n, 3, -1)
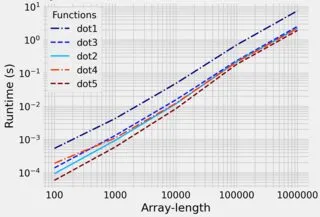
在 MacBook Pro 2012 上,这给了我:
In [62]: %timeit dot1()
783 ms ± 20.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [63]: %timeit dot2()
261 ms ± 1.93 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [64]: %timeit dot3()
293 ms ± 2.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [65]: %timeit dot4()
281 ms ± 6.15 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
除了朴素方法外,其他方法都很相似。有没有一种方法可以显著加速这个过程?
编辑
(如果可用,cuda方法是最佳的。以下是非cuda版本的比较)
根据各种建议,我修改了dot2,添加了Op@A方法以及基于#59356461的一个版本。
@njit(fastmath=True, parallel=True)
def dot2(Op, A):
""" same as above, but jitted """
new = np.empty_like(A)
for i in prange(Op.shape[0]):
new[i] = np.dot(Op[i], A[i])
return new
def dot5(Op, A):
""" using matmul """
return Op@A
@njit(fastmath=True, parallel=True)
def dot6(Op, A):
""" another numba.jit with parallel (based on #59356461) """
new = np.empty_like(A)
for i_n in prange(A.shape[0]):
for i_k in range(A.shape[2]):
for i_x in range(3):
acc = 0.0j
for i_y in range(3):
acc += Op[i_n, i_x, i_y] * A[i_n, i_y, i_k]
new[i_n, i_x, i_k] = acc
return new
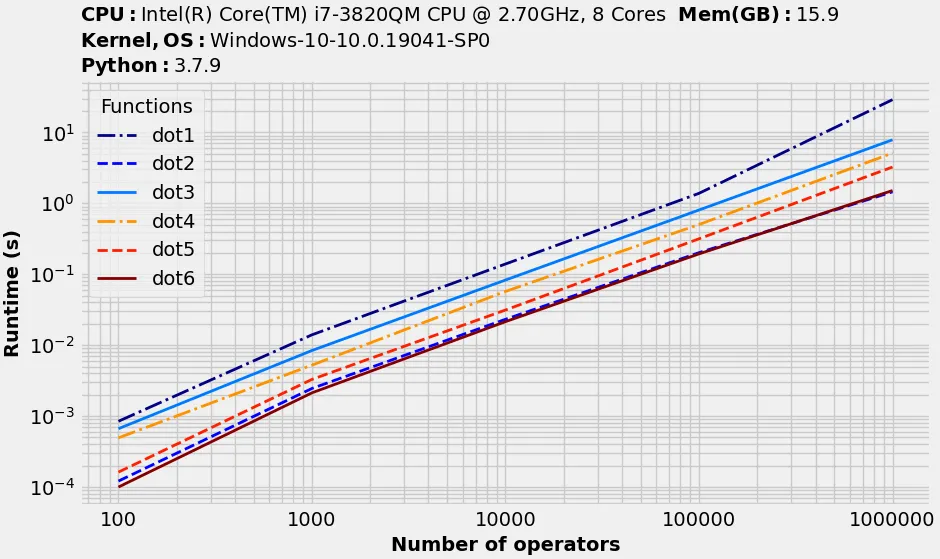
这是在另一台机器上使用
benchit得到的结果:def gen(n, k):
Op = np.random.rand(n, 3, 3) + 1j * np.random.rand(n, 3, 3)
A = np.random.rand(n, 3, k) + 1j * np.random.rand(n, 3, k)
return Op, A
# benchit
import benchit
funcs = [dot1, dot2, dot3, dot4, dot5, dot6]
inputs = {n: gen(n, 100) for n in [100,1000,10000,100000,1000000]}
t = benchit.timings(funcs, inputs, multivar=True, input_name='Number of operators')
t.plot(logy=True, logx=True)
Op@A吗? - hpauljeinsum在处理复杂数据时表现得更差。 - piliv