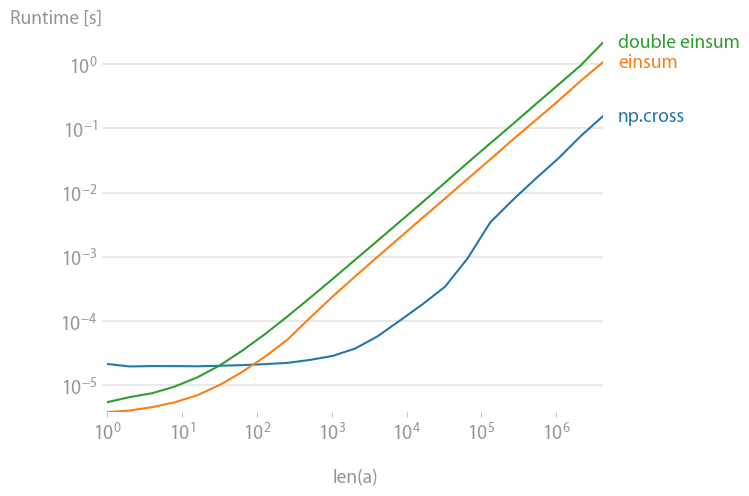
看起来,对于一个向量数组的叉积计算而言,显式计算要比使用
在笔记本电脑上,显式计算每个叉积需要大约60ns。这大约是最快的速度吗?在这种情况下,似乎没有理由去使用Cython或PyPy或编写特殊的
我还看到有关使用einsum的参考资料,但我不太明白如何使用它,并怀疑它并不更快。
np.cross快得多。我已经尝试了矢量-先和矢量-后,但似乎没有区别,尽管在类似问题的答案中提出了这种方法。我是在使用错误的方法吗,还是它只是更慢?在笔记本电脑上,显式计算每个叉积需要大约60ns。这大约是最快的速度吗?在这种情况下,似乎没有理由去使用Cython或PyPy或编写特殊的
ufunc。我还看到有关使用einsum的参考资料,但我不太明白如何使用它,并怀疑它并不更快。
a = np.random.random(size=300000).reshape(100000,3) # vector last
b = np.random.random(size=300000).reshape(100000,3)
c, d = a.swapaxes(0, 1), b.swapaxes(0, 1) # vector first
def npcross_vlast(): return np.cross(a, b)
def npcross_vfirst(): return np.cross(c, d, axisa=0, axisb=0)
def npcross_vfirst_axisc(): return np.cross(c, d, axisa=0, axisb=0, axisc=0)
def explicitcross_vlast():
e = np.zeros_like(a)
e[:,0] = a[:,1]*b[:,2] - a[:,2]*b[:,1]
e[:,1] = a[:,2]*b[:,0] - a[:,0]*b[:,2]
e[:,2] = a[:,0]*b[:,1] - a[:,1]*b[:,0]
return e
def explicitcross_vfirst():
e = np.zeros_like(c)
e[0,:] = c[1,:]*d[2,:] - c[2,:]*d[1,:]
e[1,:] = c[2,:]*d[0,:] - c[0,:]*d[2,:]
e[2,:] = c[0,:]*d[1,:] - c[1,:]*d[0,:]
return e
print "explicit"
print timeit.timeit(explicitcross_vlast, number=10)
print timeit.timeit(explicitcross_vfirst, number=10)
print "np.cross"
print timeit.timeit(npcross_vlast, number=10)
print timeit.timeit(npcross_vfirst, number=10)
print timeit.timeit(npcross_vfirst_axisc, number=10)
print all([npcross_vlast()[7,i] == npcross_vfirst()[7,i] ==
npcross_vfirst_axisc()[i,7] == explicitcross_vlast()[7,i] ==
explicitcross_vfirst()[i,7] for i in range(3)]) # check one
explicit
0.0582590103149
0.0560920238495
np.cross
0.399816989899
0.412983894348
0.411231040955
True
np.cross的代码。它正在做你正在做的事情,还加入了一些处理大小为2的情况的覆盖,并进行了一些轴交换,以便可以使用像a[1]*b[2] - a[2]*b[1]这样的表达式。只要大维度是向量化的,对小维度(大小为3)进行一些明确的步骤不会影响速度。 - hpauljnumpy可能会解决这个问题。我在1.9.2上看到非常相似的时间。 - celswapaxes对速度没有任何影响,因为内存布局仍然相同。如果数组从一开始就是这样生成的话,vfirst会稍微快一些。 - hpauljswapaxes仅返回视图。 - uhoh