我有一个包含列 [A, B, C, D, E, F, G, H] 的 DataFrame。
使用列 [D, G, H] 创建了一个索引:
>>> print(dgh_columns)
Index(['D', 'G', 'H'], dtype='object')
如何检索原始 DataFrame,不包括列 D、G、H?
是否存在索引子集操作?
理想情况下,应该是:
df[df.index - dgh_columns]
但是这似乎不起作用。
我认为您可以使用Index.difference:
df[df.columns.difference(dgh_columns)]
示例:
df = pd.DataFrame({'A':[1,2,3],
'B':[4,5,6],
'C':[7,8,9],
'D':[1,3,5],
'E':[7,8,9],
'F':[1,3,5],
'G':[5,3,6],
'H':[7,4,3]})
print (df)
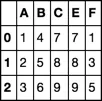
A B C D E F G H
0 1 4 7 1 7 1 5 7
1 2 5 8 3 8 3 3 4
2 3 6 9 5 9 5 6 3
dgh_columns = pd.Index(['D', 'G', 'H'])
print (df[df.columns.difference(dgh_columns)])
A B C E F
0 1 4 7 7 1
1 2 5 8 8 3
2 3 6 9 9 5
Numpy解决方案,使用numpy.setxor1d或numpy.setdiff1d:
dgh_columns = pd.Index(['D', 'G', 'H'])
print (df[np.setxor1d(df.columns, dgh_columns)])
A B C E F
0 1 4 7 7 1
1 2 5 8 8 3
2 3 6 9 9 5
dgh_columns = pd.Index(['D', 'G', 'H'])
print (df[np.setdiff1d(df.columns, dgh_columns)])
A B C E F
0 1 4 7 7 1
1 2 5 8 8 3
2 3 6 9 9 5
使用drop
df.drop(list('DGH'), axis=1)
df = pd.DataFrame({'A':[1,2,3],
'B':[4,5,6],
'C':[7,8,9],
'D':[1,3,5],
'E':[7,8,9],
'F':[1,3,5],
'G':[5,3,6],
'H':[7,4,3]})
df.drop(list('DGH'), 1)