如果我有这个数据框:
import pandas as pd
tuples_index = [(1,1990), (2,1999), (2,2002), (3,1992), (3,1994), (3,1996)]
index = pd.MultiIndex.from_tuples(tuples_index, names=['id', 'FirstYear'])
df = pd.DataFrame([2007, 2006, 2006, 2000, 2000, 2000], index=index, columns=['LastYear'] )
df
Out[2]:
LastYear
id FirstYear
1 1990 2007
2 1999 2006
2002 2006
3 1992 2000
1994 2000
1996 2000
我希望能够获取数据框的子集,其中基于id的分组长度大于1,我可以这样做,但速度较慢:
%timeit df.groupby(level=0).filter(lambda x: len(x) > 1)
1000 loops, best of 3: 1.36 ms per loop
我的数据框有数千万行和大量分组(大多数分组长度为1),因此时间会累积。 我可以通过以下方式更快地获得布尔索引:
%timeit df.groupby(level=0).size() > 1
1000 loops, best of 3: 364 µs per loop
但是布尔索引器只有 id 作为它的索引:
id
1 False
2 True
3 True
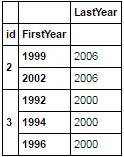
我猜可能我提供的背景信息过多了,但如果我想使用布尔索引器和单个索引从具有MultiIndex的数据帧中获取子集,该怎么做呢?期望的输出为:
LastYear
id FirstYear
2 1999 2006
2002 2006
3 1992 2000
1994 2000
1996 2000
df.groupby(level = 0).filter(lambda x:len(x)> 1)很慢,因为它返回一个新的DataFrame,其中包含从原始DataFrame的任意位置复制的数据。df.groupby(level=0).size() > 1相对较快,因为它生成的是一个较小的DataFrame -- 需要复制的数据较少。使用布尔索引器生成过滤后的DataFrame将无法节省时间,因为该步骤将需要复制。 - unutbu