是的,你使用它的方式不正确,Series.replace()默认情况下不是就地操作(inplace operation),它会返回替换后的数据帧/序列,你需要将其赋值回你的数据帧/序列才能产生效果。如果你需要在原地进行替换,那么你需要指定inplace关键字参数为True。例如 -
data['sex'].replace(0, 'Female',inplace=True)
data['sex'].replace(1, 'Male',inplace=True)
另外,你可以通过使用 list 来将上述内容组合成一个单一的 replace 函数调用,同时作为 to_replace 参数和 value 参数,例如 -
data['sex'].replace([0,1],['Female','Male'],inplace=True)
示例/演示 -
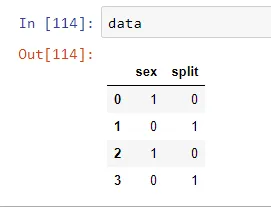
In [10]: data = pd.DataFrame([[1,0],[0,1],[1,0],[0,1]], columns=["sex", "split"])
In [11]: data['sex'].replace([0,1],['Female','Male'],inplace=True)
In [12]: data
Out[12]:
sex split
0 Male 0
1 Female 1
2 Male 0
3 Female 1
您也可以使用字典,例如 -
In [15]: data = pd.DataFrame([[1,0],[0,1],[1,0],[0,1]], columns=["sex", "split"])
In [16]: data['sex'].replace({0:'Female',1:'Male'},inplace=True)
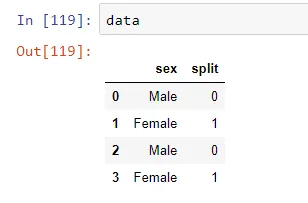
In [17]: data
Out[17]:
sex split
0 Male 0
1 Female 1
2 Male 0
3 Female 1
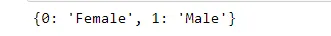
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame的警告。 - Stefan Falk