我试图使用下面的代码来推断我数据中的缺失值 (NA),但它却不能正常工作。
我的数据:
landkreis jahr deDomains
<chr> <dbl> <dbl>
1 Ahrweile… 2007 NA
2 Ahrweile… 2008 NA
3 Ahrweile… 2009 NA
4 Ahrweile… 2010 NA
5 Ahrweile… 2011 NA
6 Ahrweile… 2012 NA
7 Ahrweile… 2013 22224
8 Ahrweile… 2014 22460
9 Ahrweile… 2015 2379
10 Ahrweile… 2016 22769
11 Ahrweile… 2017 23268
12 Aichach-… 2007 NA
13 Aichach-… 2008 NA
14 Aichach-… 2009 NA
15 Aichach-… 2010 NA
16 Aichach-… 2011 NA
17 Aichach-… 2012 NA
18 Aichach-… 2013 21341
19 Aichach-… 2014 21393
20 Aichach-… 2015 21338
我试图使用以下代码推断deDomains变量中的NA值,但它不起作用。
df_complete <- df_complete %>%
group_by(landkreis) %>%
mutate(`deDomains` = approxExtrap(which(!is.na(`deDomains`)),
`deDomains`[!is.na(`deDomains`)])$y)
我正在使用来自
Hmisc 包的 approxExtrap() 命令进行线性外推。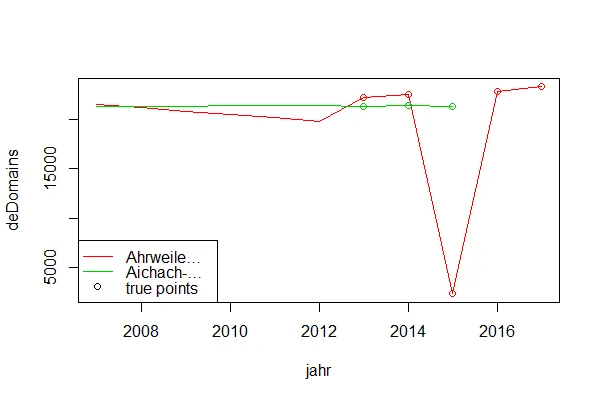
dput(df_complete)的结果。 - Cettt