罗兰,你的基线解决了“时间趋势t的添加”问题,无论是以编程方式还是非编程方式:以下是我包“causfinder”中的
adfcs函数(一种用于条件和部分格兰杰因果关系系统分析的包):
我编写了增广迪基-富勒测试代码,考虑到自回归过程的所有滞后阶数都使用相同的(公共)子样本使用情况(技术信息:在计量经济学的所有滞后选择程序中,必须使用相同的子样本来确定正确的最小滞后)。请参见下面ct案例的seq_along:
adfcs <- function(t, max = floor(12*(length(t)/100)^(1/4)), type = c("c")) {
x <- ts(t)
x1d <- diff(x, differences=1)
x1l <- lag(x, -1)
x_names <- c("x1d", "x1l", sapply(1:max, function(i) paste("x1d", i, "l", sep="")))
for (i in as.integer(1:max)) { assign(x_names[i+2], lag(x1d, -i)) }
DLDlag <- do.call(ts.intersect, sapply(x_names, as.symbol))
DLDlag.df <- data.frame(DLDlag, obspts = c(time(DLDlag)))
DifferenceLags <- as.vector(names(DLDlag.df), mode="any")[3: (length(DLDlag.df)-1)]
lmresults <- array(list())
SBCvalues <- array(list())
AICvalues <- array(list())
for (i in as.integer(0:max)) {
if (type==c("nc")) {
if (i == 0) { lmresults[[max+1]] <- lm(as.formula(paste("x1d ~x1l")),data=DLDlag.df)
SBCvalues[[max+1]] <- BIC(lmresults[[max+1]])
AICvalues[[max+1]] <- AIC(lmresults[[max+1]]) }
if (i > 0) { lmresults[[i]] <- lm(as.formula(paste("x1d ~ x1l+", paste(DifferenceLags[1:i], collapse="+"))),data=DLDlag.df)
SBCvalues[[i]] <- BIC(lmresults[[i]])
AICvalues[[i]] <- AIC(lmresults[[i]]) }
}
if (type==c("c")) {
if (i == 0) { lmresults[[max+1]] <- lm(as.formula(paste("x1d ~1+x1l")),data=DLDlag.df)
SBCvalues[[max+1]] <- BIC(lmresults[[max+1]])
AICvalues[[max+1]] <- AIC(lmresults[[max+1]]) }
if (i > 0) { lmresults[[i]] <- lm(as.formula(paste("x1d ~ 1+x1l+", paste(DifferenceLags[1:i], collapse="+"))),data=DLDlag.df)
SBCvalues[[i]] <- BIC(lmresults[[i]])
AICvalues[[i]] <- AIC(lmresults[[i]]) }
}
if (type==c("ct")) {
if (i == 0) { lmresults[[max+1]] <- lm(as.formula(paste("x1d ~ 1+x1l+seq_along(x1d)",collapse="")),data=DLDlag.df)
SBCvalues[[max+1]] <- BIC(lmresults[[max+1]])
AICvalues[[max+1]] <- AIC(lmresults[[max+1]]) }
if (i > 0) { lmresults[[i]] <- lm(as.formula(paste("x1d ~ 1+x1l+seq_along(x1d)+",paste(DifferenceLags[1:i], collapse="+"))),data=DLDlag.df)
SBCvalues[[i]] <- BIC(lmresults[[i]])
AICvalues[[i]] <- AIC(lmresults[[i]]) }
}
}
list(which.min(SBCvalues), which.min(AICvalues))
as.data.frame(cbind(SBCvalues, AICvalues))
typespecified <- type
if (which.min(SBCvalues)==max+1) {
scs <- (max+2)-(0+1)
adfcs <- unitrootTest(x[scs:length(x)], lags = 0, type = typespecified)
} else {
scs <- (max+2)-(which.min(SBCvalues)+1)
adfcs <- unitrootTest(x[scs:length(x)], lags =which.min(SBCvalues), type = typespecified)
}
adfcs
}
注意:非编程添加时间趋势:
x <- rnorm(10)
x1l <- lag(x,-1)
lm(x ~ 1+ x1l + seq_along(x))
# 调用:
# lm(formula = x ~ 1 + x1l + seq_along(x))
# 系数:
# (截距) x1l seq_along(x)
# -2.107e-16 1.000e+00 2.645e-17
..... 我检查了adfcs,当在Eviews中进行适当的计算时,它与Eviews给出相同的结果:
注意: 在 Eviews (版本<=7.2) 中, ADF 测试没有使用相同的(常规)子样本,因此 Eviews 的 ADF 是错误的! 上述代码在 Eviews 中的正确实现方式如下:
1. 双击一个变量;查看;单位根测试;ADF;“水平,截距”;滞后长度:自动选择 Schwarz:最大滞后数=14”。(14 根据数据集而变)
2. 通过删除前面的几个样本来排列子样本:假设数据是1960年第1季度至2009年第4季度(200个观测值)。然后从样本中删除前14+1个观测值:样本 - 样本范围对:1963年第4季度2009年第4季度。提供相同的子样本后,执行 ADF。
3. 再次双击同一个变量;查看;单位根测试;ADF;“水平,截距”;滞后长度:自动选择 Schwarz:最大滞后数=14”。(这里可能会出现不同于 14 的数字,因为子采样的影响而产生的; 删除该框中的数字,并键入 14)。按 OK。
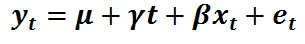
t <- seq_along(x) ; lm(y~x+t)。 - Roland