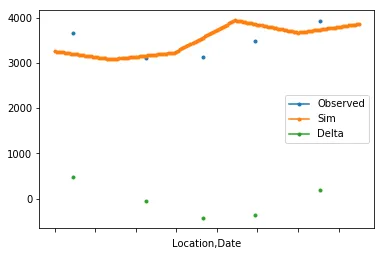
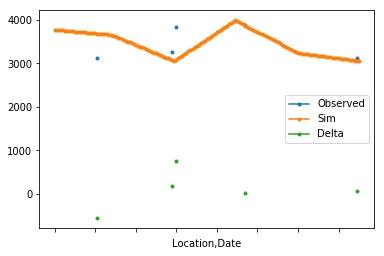
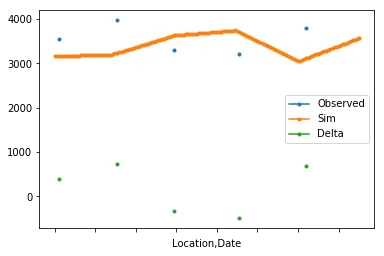
我有两个数据框(df1和df2),格式如下。
df1是模拟结果。因此,df1在时间步长方面更密集地分布(每月开始)。
df2是实际观测数据。因此可用数据较少(只有收集的数据)。
df1和df2都具有不同的时间序列(时间步长),并按每个位置编制。
样本数据
我的想法是使用df.groupby方法分组每个“位置”,使用series.resample将df1中的Sim列重新采样为每日频率。在df1每日频率上进行线性插值。在观察到的日期上计算Delta。然后将它们绘制出来。
样本数据
df1 = pd.DataFrame({'Date': ['2018-02-01', '2018-03-01', '2018-04-01', '2018-05-01', '2018-06-01', '2018-07-01', '2018-02-01', '2018-03-01', '2018-04-01', '2018-05-01', '2018-06-01', '2018-07-01', '2018-02-01', '2018-03-01', '2018-04-01', '2018-05-01', '2018-06-01', '2018-07-01'], 'Location': [1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3], 'Sim': [3253, 3078, 3222, 3940, 3665, 3856, 3775, 3658, 3056, 3993, 3240, 3054, 3162, 3193, 3627, 3740, 3042, 3569]})
df2 = pd.DataFrame({'Date': ['2018-02-10', '2018-03-18', '2018-04-15', '2018-05-11', '2018-06-12', '2018-07-11', '2018-02-22', '2018-03-31', '2018-04-02', '2018-05-06', '2018-06-30', '2018-07-21', '2018-02-03', '2018-03-04', '2018-04-01', '2018-05-03', '2018-06-05', '2018-07-25'], 'Location': [1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3], 'Observed': [3668, 3102, 3128, 3485, 3926, 3344, 3134, 3258, 3833, 3883, 3122, 3417, 3551, 3971, 3294, 3207, 3803, 3250]})
df1:
Date Location Sim
0 2018-02-01 1 3253
1 2018-03-01 1 3078
2 2018-04-01 1 3222
3 2018-05-01 1 3940
4 2018-06-01 1 3665
5 2018-07-01 1 3856
6 2018-02-01 2 3775
7 2018-03-01 2 3658
8 2018-04-01 2 3056
9 2018-05-01 2 3993
10 2018-06-01 2 3240
11 2018-07-01 2 3054
12 2018-02-01 3 3162
13 2018-03-01 3 3193
14 2018-04-01 3 3627
15 2018-05-01 3 3740
16 2018-06-01 3 3042
17 2018-07-01 3 3569
df2:
Date Location Observed
0 2018-02-10 1 3668
1 2018-03-18 1 3102
2 2018-04-15 1 3128
3 2018-05-11 1 3485
4 2018-06-12 1 3926
5 2018-07-11 1 3344
6 2018-02-22 2 3134
7 2018-03-31 2 3258
8 2018-04-02 2 3833
9 2018-05-06 2 3883
10 2018-06-30 2 3122
11 2018-07-21 2 3417
12 2018-02-03 3 3551
13 2018-03-04 3 3971
14 2018-04-01 3 3294
15 2018-05-03 3 3207
16 2018-06-05 3 3803
17 2018-07-25 3 3250
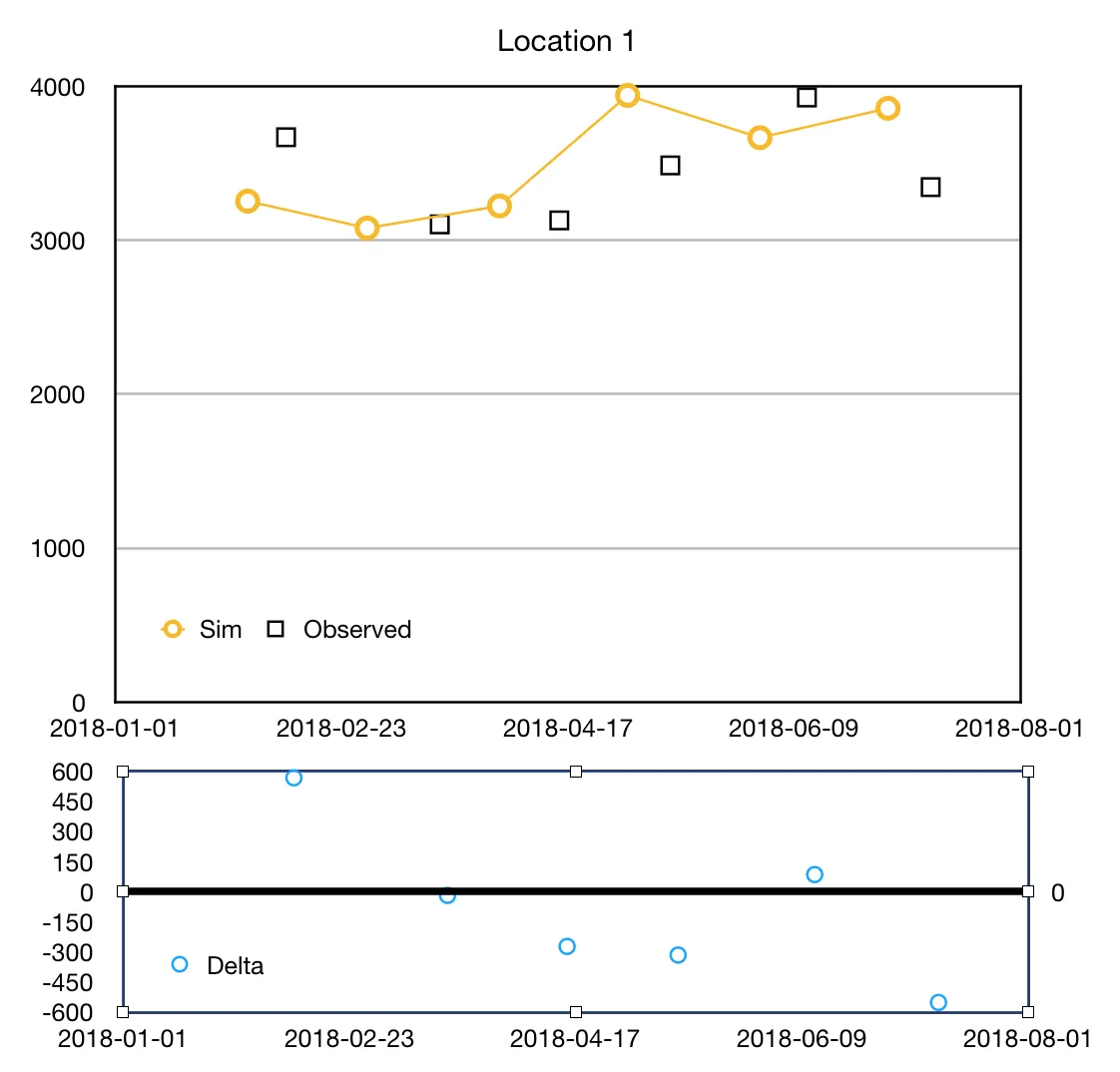
我的想法是使用df.groupby方法分组每个“位置”,使用series.resample将df1中的Sim列重新采样为每日频率。在df1每日频率上进行线性插值。在观察到的日期上计算Delta。然后将它们绘制出来。