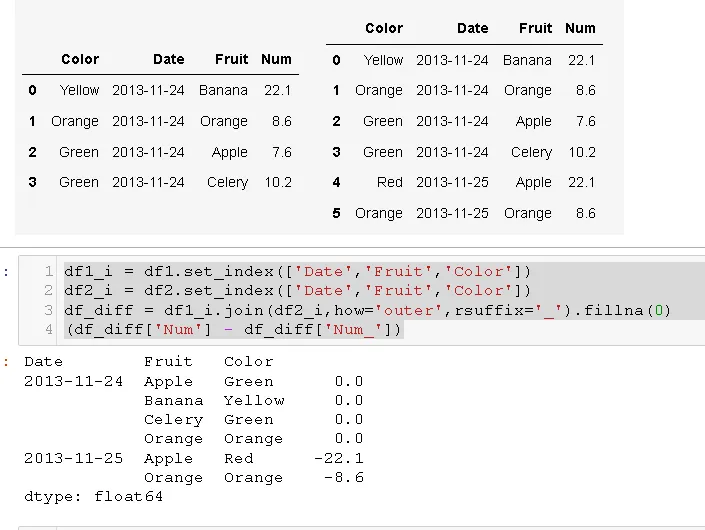
我有两个数据框。例子:
df1:
Date Fruit Num Color
2013-11-24 Banana 22.1 Yellow
2013-11-24 Orange 8.6 Orange
2013-11-24 Apple 7.6 Green
2013-11-24 Celery 10.2 Green
df2:
Date Fruit Num Color
2013-11-24 Banana 22.1 Yellow
2013-11-24 Orange 8.6 Orange
2013-11-24 Apple 7.6 Green
2013-11-24 Celery 10.2 Green
2013-11-25 Apple 22.1 Red
2013-11-25 Orange 8.6 Orange
每个数据框都有日期作为索引。两个数据框具有相同的结构。
我想要做的是比较这两个数据框,并找出df2中不在df1中的行。我想要比较日期(索引)和第一列(香蕉,苹果等),以查看它们是否存在于df2与df1中。
我尝试了以下方法:
对于第一种方法,我得到了这个错误:"Exception: Can only compare identically-labeled DataFrame objects"。我已经尝试过删除日期作为索引,但仍然出现相同的错误。
在第三种方法中,我得到了assert返回False,但是无法弄清楚如何实际查看不同的行。
欢迎任何指针。