我有两个数据帧df1和df2,其中df2是df1的子集。如何得到一个新的数据帧(df3),该数据帧是两个数据帧之间的差异?
换句话说,一个数据帧,它包含在df1中而不在df2中的所有行/列?
我有两个数据帧df1和df2,其中df2是df1的子集。如何得到一个新的数据帧(df3),该数据帧是两个数据帧之间的差异?
换句话说,一个数据帧,它包含在df1中而不在df2中的所有行/列?
通过使用 drop_duplicates
pd.concat([df1,df2]).drop_duplicates(keep=False)
更新:
上述方法仅适用于那些没有重复数据的数据框。例如:
df1=pd.DataFrame({'A':[1,2,3,3],'B':[2,3,4,4]})
df2=pd.DataFrame({'A':[1],'B':[2]})
输出结果会像下面这样,是错误的
错误的输出结果:
pd.concat([df1, df2]).drop_duplicates(keep=False)
Out[655]:
A B
1 2 3
正确的输出
Out[656]:
A B
1 2 3
2 3 4
3 3 4
如何实现?
方法1:使用tuple和isin
df1[~df1.apply(tuple,1).isin(df2.apply(tuple,1))]
Out[657]:
A B
1 2 3
2 3 4
3 3 4
方法2:merge与indicator合并
df1.merge(df2,indicator = True, how='left').loc[lambda x : x['_merge']!='both']
Out[421]:
A B _merge
1 2 3 left_only
2 3 4 left_only
3 3 4 left_only
pd.concat([df1,df2]).drop_duplicates(subset = ['col1','col2'], keep=False) - Szpaqnindicator=True)是非常灵活和有用的工具,我希望它能出现在这个答案的顶部,但使用'outer'而不是'left'连接,以覆盖所有三种情况。 - mirekphdapply(tuple,1) 的含义?这段代码的含义是将整数1转换为一个元组。apply() 函数将第一个参数作为函数,第二个参数作为该函数的参数,并返回该函数的结果。在这个例子中,tuple 是一个函数,1 是该函数的参数,因此 apply(tuple,1) 返回一个只包含一个元素(即数字1)的元组 (1,)。 - liangli对于行,请尝试使用以下内容,其中Name是联合索引列(可以是多个公共列的列表,或指定left_on和right_on):
对于行,请尝试使用以下内容,其中Name是联合索引列(可以是多个公共列的列表,或指定left_on和right_on):
m = df1.merge(df2, on='Name', how='outer', suffixes=['', '_'], indicator=True)
indicator=True设置非常有用,因为它添加了一个称为_merge的列,其中包含了df1和df2之间所有变化,分为3种可能的类型:"left_only"、"right_only"或"both"。针对列,请尝试以下操作:
set(df1.columns).symmetric_difference(df2.columns)
merge和indicator=True是比较数据框按给定字段的经典解决方案。 - jpp被接受的答案 对于包含 NaN 的数据框,方法 1 不起作用,因为 pd.np.nan != pd.np.nan。我不确定这是否是最好的方法,但可以通过避免此问题来解决。
df1[~df1.astype(str).apply(tuple, 1).isin(df2.astype(str).apply(tuple, 1))]
速度较慢,因为需要将数据转换为字符串,但是由于这个转换,pd.np.nan == pd.np.nan成立。
让我们来看看代码。首先我们将值转换为字符串,并对每一行应用tuple函数。
df1.astype(str).apply(tuple, 1)
df2.astype(str).apply(tuple, 1)
通过这样做,我们得到了一个包含元组列表的pd.Series对象。每个元组包含来自df1/df2的整行数据。
然后我们在df1上应用isin方法来检查每个元组是否“在”df2中。
结果是一个布尔值的pd.Series。如果来自df1的元组在df2中,则为True。最后,我们用~符号对结果取反,并在df1上进行筛选。简而言之,我们只得到那些不在df2中的df1行。
为了使其更易读,我们可以将其写成:
df1_str_tuples = df1.astype(str).apply(tuple, 1)
df2_str_tuples = df2.astype(str).apply(tuple, 1)
df1_values_in_df2_filter = df1_str_tuples.isin(df2_str_tuples)
df1_values_not_in_df2 = df1[~df1_values_in_df2_filter]
import pandas as pd
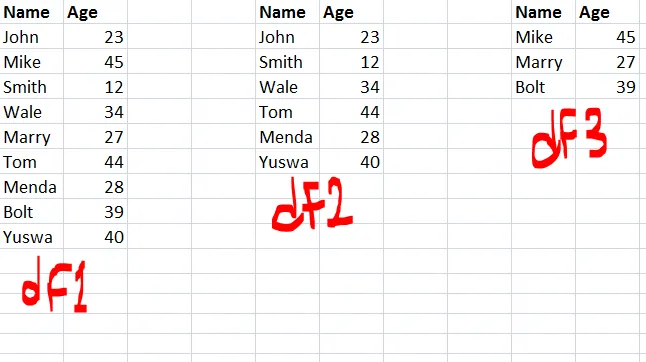
# given
df1 = pd.DataFrame({'Name':['John','Mike','Smith','Wale','Marry','Tom','Menda','Bolt','Yuswa',],
'Age':[23,45,12,34,27,44,28,39,40]})
df2 = pd.DataFrame({'Name':['John','Smith','Wale','Tom','Menda','Yuswa',],
'Age':[23,12,34,44,28,40]})
# find elements in df1 that are not in df2
df_1notin2 = df1[~(df1['Name'].isin(df2['Name']) & df1['Age'].isin(df2['Age']))].reset_index(drop=True)
# output:
print('df1\n', df1)
print('df2\n', df2)
print('df_1notin2\n', df_1notin2)
# df1
# Age Name
# 0 23 John
# 1 45 Mike
# 2 12 Smith
# 3 34 Wale
# 4 27 Marry
# 5 44 Tom
# 6 28 Menda
# 7 39 Bolt
# 8 40 Yuswa
# df2
# Age Name
# 0 23 John
# 1 12 Smith
# 2 34 Wale
# 3 44 Tom
# 4 28 Menda
# 5 40 Yuswa
# df_1notin2
# Age Name
# 0 45 Mike
# 1 27 Marry
# 2 39 Bolt
pandas.DataFrame.compare。请参见此处。df.compare(df2)
col1 col3
self other self other
0 a c NaN NaN
2 NaN NaN 3.0 4.0
编辑2,我找到了一种新的解决方案,不需要设置索引。
newdf=pd.concat([df1,df2]).drop_duplicates(keep=False)
好的,我已经找到最高得票答案,其中包含了我已经想出的答案。是的,在每两个数据框中都没有重复项的情况下,我们只能使用这段代码。
我有一个巧妙的方法。首先,我们将问题中给出的两个数据帧的“名称”设置为索引。由于两个数据帧中都有相同的“名称”,因此我们可以从“较大”的数据帧中删除“较小”数据帧的索引。 以下是代码:
df1.set_index('Name',inplace=True)
df2.set_index('Name',inplace=True)
newdf=df1.drop(df2.index)
newDf = df1.set_index('Name1')
.drop(df2['Name2'], errors='ignore')
.reset_index(drop=False)
在pandas中有一种新的方法DataFrame.compare,可以比较两个不同的数据框并返回每列数据记录中哪些值发生了变化。
第一个数据框
Id Customer Status Date
1 ABC Good Mar 2023
2 BAC Good Feb 2024
3 CBA Bad Apr 2022
第二个数据框
Id Customer Status Date
1 ABC Bad Mar 2023
2 BAC Good Feb 2024
5 CBA Good Apr 2024
比较数据框
print("Dataframe difference -- \n")
print(df1.compare(df2))
print("Dataframe difference keeping equal values -- \n")
print(df1.compare(df2, keep_equal=True))
print("Dataframe difference keeping same shape -- \n")
print(df1.compare(df2, keep_shape=True))
print("Dataframe difference keeping same shape and equal values -- \n")
print(df1.compare(df2, keep_shape=True, keep_equal=True))
结果
Dataframe difference --
Id Status Date
self other self other self other
0 NaN NaN Good Bad NaN NaN
2 3.0 5.0 Bad Good Apr 2022 Apr 2024
Dataframe difference keeping equal values --
Id Status Date
self other self other self other
0 1 1 Good Bad Mar 2023 Mar 2023
2 3 5 Bad Good Apr 2022 Apr 2024
Dataframe difference keeping same shape --
Id Customer Status Date
self other self other self other self other
0 NaN NaN NaN NaN Good Bad NaN NaN
1 NaN NaN NaN NaN NaN NaN NaN NaN
2 3.0 5.0 NaN NaN Bad Good Apr 2022 Apr 2024
Dataframe difference keeping same shape and equal values --
Id Customer Status Date
self other self other self other self other
0 1 1 ABC ABC Good Bad Mar 2023 Mar 2023
1 2 2 BAC BAC Good Good Feb 2024 Feb 2024
2 3 5 CBA CBA Bad Good Apr 2022 Apr 2024
import numpy as np
import pandas as pd
def get_dataframe_setdiff2d(df_new: pd.DataFrame,
df_old: pd.DataFrame,
rtol=1e-03, atol=1e-05) -> pd.DataFrame:
"""Returns set difference of two pandas DataFrames"""
union_index = np.union1d(df_new.index, df_old.index)
union_columns = np.union1d(df_new.columns, df_old.columns)
new = df_new.reindex(index=union_index, columns=union_columns)
old = df_old.reindex(index=union_index, columns=union_columns)
mask_diff = ~np.isclose(new, old, rtol, atol)
df_bool = pd.DataFrame(mask_diff, union_index, union_columns)
df_diff = pd.concat([new[df_bool].stack(),
old[df_bool].stack()], axis=1)
df_diff.columns = ["New", "Old"]
return df_diff
例子:
In [1]
df1 = pd.DataFrame({'A':[2,1,2],'C':[2,1,2]})
df2 = pd.DataFrame({'A':[1,1],'B':[1,1]})
print("df1:\n", df1, "\n")
print("df2:\n", df2, "\n")
diff = get_dataframe_setdiff2d(df1, df2)
print("diff:\n", diff, "\n")
Out [1]
df1:
A C
0 2 2
1 1 1
2 2 2
df2:
A B
0 1 1
1 1 1
diff:
New Old
0 A 2.0 1.0
B NaN 1.0
C 2.0 NaN
1 B NaN 1.0
C 1.0 NaN
2 A 2.0 NaN
C 2.0 NaN
如果您只对仅存在于一个数据框中但不存在于另一个数据框中的行感兴趣,则需要查找集合差异:
pd.concat([df1,df2]).drop_duplicates(keep=False)
⚠️ 仅当两个数据框中均不包含任何重复项时,才起作用。
如果您对关系代数差 / 集合差感兴趣,即 df1-df2 或 df1\df2:
pd.concat([df1,df2,df2]).drop_duplicates(keep=False)