我有一组简单的
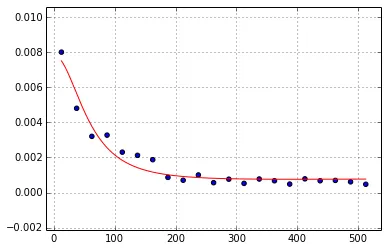
下面的图显示了数据点和最佳拟合曲线(蓝色)。使用的曲线函数(
下面的
我得到的结果是:
x,y 数据需要拟合,至少乍一看是这样。问题在于 scipy.optimize.curve_fit 返回了一个非常大的拟合参数值,我不知道这是否正确或者我拟合数据的方法是否有问题。下面的图显示了数据点和最佳拟合曲线(蓝色)。使用的曲线函数(
MWE 中的 func)有四个参数 a, b, c, d 需要被拟合:
a大约给出曲线达到半峰值的x值。b表示曲线稳定的x值。这个func的值由d参数给出,即:func(b) = dc与原点处曲线的最大值相关:func(0) = c*constant + dd是曲线稳定的位置(图中黑线)。
b 参数(见问题结尾),也是我最感兴趣的需要分配合理值的参数之一。下面的
MWE 显示了被拟合的函数和结果:import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# Function to be fitted.
def func(x, a, b, c, d):
return c * (1 / np.sqrt(1 + (np.asarray(x) / a) ** 2) -
1 / np.sqrt(1 + (b / a) ** 2)) ** 2 + d
# Define x,y data.
x_list = [12.5, 37.5, 62.5, 87.5, 112.5, 137.5, 162.5, 187.5, 212.5, 237.5,
262.5, 287.5, 312.5, 337.5, 362.5, 387.5, 412.5, 437.5, 462.5, 487.5,
512.5]
y_list = [0.008, 0.0048, 0.0032, 0.00327, 0.0023, 0.00212, 0.00187,
0.00086, 0.00070, 0.00100, 0.00056, 0.00076, 0.00052, 0.00077, 0.00067,
0.00048, 0.00078, 0.00067, 0.00069, 0.00061, 0.00047]
# Initial guess for the 4 parameters.
guess = (50., 200., 80. / 10000., 6. / 10000.)
# Fit curve to x,y data.
f_prof, f_err = curve_fit(func, x_list, y_list, guess)
# Values for the a,b,c,d fitted parameters.
print f_prof
# Errors (standard deviations) for the fitted parameters.
print np.sqrt(f_err[0][0]), np.sqrt(f_err[1][1]), np.sqrt(f_err[2][2]),\
np.sqrt(f_err[3][3])
# Generate plot.
plt.scatter(x_list, y_list)
plt.plot(x_list, func(x_list, f_prof[0], f_prof[1], f_prof[2], f_prof[3]))
plt.hlines(y=f_prof[3], xmin=0., xmax=max(x_list))
plt.show()
我得到的结果是:
# a, b, c, d
52.74, 2.52e+09, 7.46e-03, 5.69e-04
# errors
11.52, 1.53e+16, 0.0028, 0.00042
b参数的值很大,误差也很大。从图中展示的数据来看,我们可以通过肉眼估计出b值(即数据集开始稳定的x值)应该约为x=300。为什么我得到的b值和它的误差如此之大?