我正在尝试将一个顶帽函数拟合到一些数据上,即 f(x) 在整个实数线上都是常数,除了一个有限长度的区间,它等于另一个常数。我的参数是顶帽函数的两个常数、中点和宽度,我正在尝试使用scipy.optimize.curve_fit来得到所有这些参数。不幸的是,curve_fit在获取帽子的宽度时遇到了麻烦。无论我做什么,它都拒绝测试除我开始的宽度之外的任何值,并且其余数据的拟合非常糟糕。以下代码片段说明了这个问题:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
def tophat(x, base_level, hat_level, hat_mid, hat_width):
ret=[]
for xx in x:
if hat_mid-hat_width/2. < xx < hat_mid+hat_width/2.:
ret.append(hat_level)
else:
ret.append(base_level)
return np.array(ret)
x = np.arange(-10., 10., 0.01)
y = tophat(x, 1.0, 5.0, 0.0, 1.0)+np.random.rand(len(x))*0.2-0.1
guesses = [ [1.0, 5.0, 0.0, 1.0],
[1.0, 5.0, 0.0, 0.1],
[1.0, 5.0, 0.0, 2.0] ]
plt.plot(x,y)
for guess in guesses:
popt, pcov = curve_fit( tophat, x, y, p0=guess )
print popt
plt.plot( x, tophat(x, popt[0], popt[1], popt[2], popt[3]) )
plt.show()
为什么curve_fit在处理这个问题时表现如此糟糕,我该如何修复它?
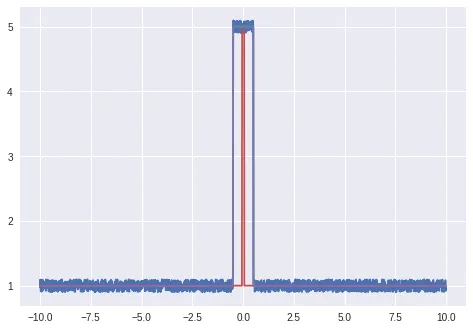
sp.curve_fit可能会失败。 您可以定义一个残差函数,作为您的顶帽和数据之间的差异,并使用类似于scipy.optimize.brute的方法将其最小化。 - Brenlla