我提出这个问题是因为我还没有找到一个可行的例子来注解 Pandas 水平分组柱状图。我知道以下两种方法:
但它们都是关于垂直条形图的。也就是说,要么没有水平条形图的解决方案,要么不完全适用。
经过几个星期的研究,我终于能够用示例代码问问题了,这个示例代码几乎符合我的要求,只是没有百分之百地工作。需要您的帮助来实现 100% 的效果。
下面是上传到Github的完整代码。结果看起来像这样:
我包括来自上面 URL 的注释代码,一个是我所能做的全部内容,另一个是参考(来自
经过几个星期的研究,我终于能够用示例代码问问题了,这个示例代码几乎符合我的要求,只是没有百分之百地工作。需要您的帮助来实现 100% 的效果。
下面是上传到Github的完整代码。结果看起来像这样:
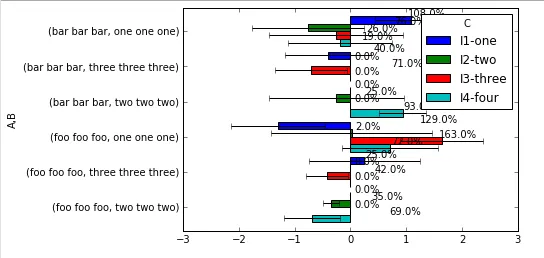
我包括来自上面 URL 的注释代码,一个是我所能做的全部内容,另一个是参考(来自
In [23]):# my all-that-I-can-do
def autolabel(rects):
#if height constant: hbars, vbars otherwise
if (np.diff([plt.getp(item, 'width') for item in rects])==0).all():
x_pos = [rect.get_x() + rect.get_width()/2. for rect in rects]
y_pos = [rect.get_y() + 1.05*rect.get_height() for rect in rects]
scores = [plt.getp(item, 'height') for item in rects]
else:
x_pos = [rect.get_width()+.3 for rect in rects]
y_pos = [rect.get_y()+.3*rect.get_height() for rect in rects]
scores = [plt.getp(item, 'width') for item in rects]
# attach some text labels
for rect, x, y, s in zip(rects, x_pos, y_pos, scores):
ax.text(x,
y,
#'%s'%s,
str(round(s, 2)*100)+'%',
ha='center', va='bottom')
# for the reference
ax.bar(1. + np.arange(len(xv)), xv, align='center')
# Annotate with text
ax.set_xticks(1. + np.arange(len(xv)))
for i, val in enumerate(xv):
ax.text(i+1, val/2, str(round(val, 2)*100)+'%', va='center',
ha='center', color='black')
Please help. Thanks.
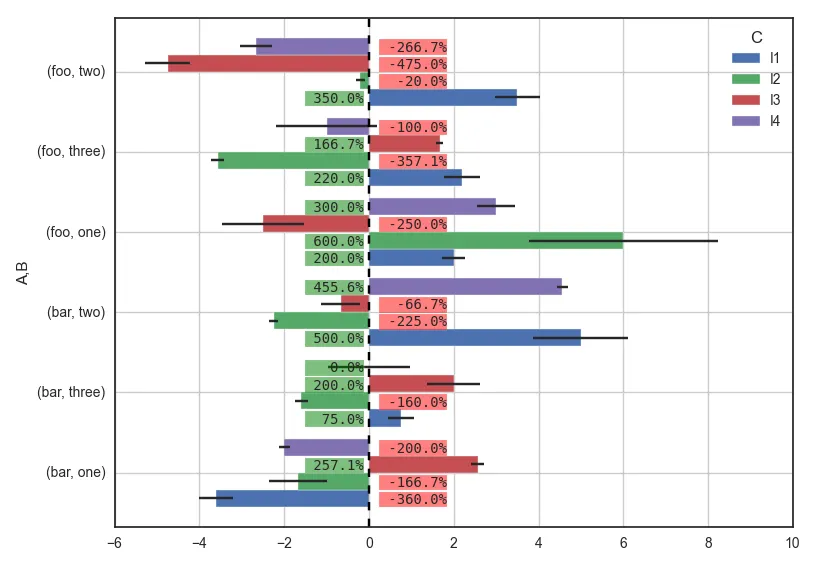
import seaborn,但是当我注释掉那行时,它仍然可以工作,但是图表看起来更难看。我想这回答了问题,但是为什么会这样呢?再次感谢。 - xptsns.set_style...),我注释说这是为了美观目的。 - jrjc