考虑以下由10行组成的DataFrame。
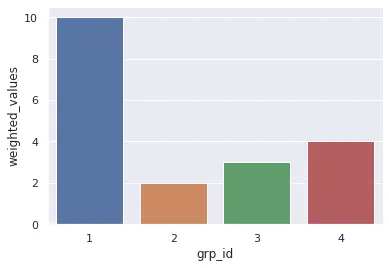
可以通过加权直方图实现
一个按grp_id分组的未加权条形图。
我尝试了以下两种方法,但都没有成功,因为两种方法都出现了
然而,我想问是否有使用pandas直接完成此操作的方法。
d = {
'grp_id':[1,2,1,1,1,3,1,1,4,1],
'weight':[1,2,1,1,1,3,1,1,4,4],
'value': [1,2,1,3,2,1,4,1,1,3]
}
df = pd.DataFrame(d)
可以通过加权直方图实现
df['value'].hist(histtype='bar', weights=df['weight'])
一个按grp_id分组的未加权条形图。
df['value'].hist(by=df['grp_id'], histtype='bar')
我尝试了以下两种方法,但都没有成功,因为两种方法都出现了
ValueError。df['value'].hist(by=df['grp_id'], weights=df['weight'], histtype='bar')
df['value'].hist(by=df['grp_id'], weights='weight', histtype='bar')
数值错误:权重应与x具有相同的形状
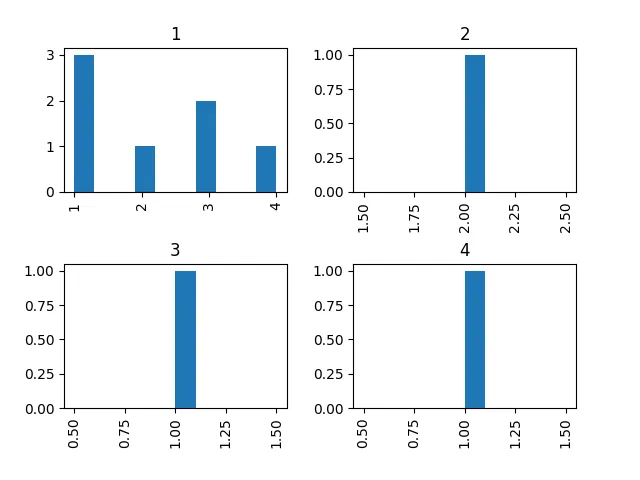
我正在使用以下临时解决方案。
fig, axes = plt.subplots(2, 2)
for ax,(idx, grp) in zip(axes.flatten(), df.groupby('grp_id')):
grp['value'].hist(weights=grp['weight'], histtype='bar', ax=ax)
然而,我想问是否有使用pandas直接完成此操作的方法。