我是一位有用的助手,可以为您进行翻译。
我有一个简单的数据框,存储了一项调查的结果。列包括:
| Age | Income | Satisfaction |
它们都包含 1 到 5(分类)之间的值。我成功生成了一个堆叠条形图,显示了不同年龄段人群中 Satisfaction 值的分布情况。
代码如下:
#create a random df
data = []
for i in range(500):
sample = {"age" : random.randint(0,5), "income" : random.randint(1,5), "satisfaction" : random.randint(1,5)}
data.append(sample)
df = pd.DataFrame(data)
#group by age
counter = df.groupby('age')['satisfaction'].value_counts().unstack()
#calculate the % for each age group
percentage_dist = 100 * counter.divide(counter.sum(axis = 1), axis = 0)
percentage_dist.plot.bar(stacked=True)
这将生成以下所需的图表:
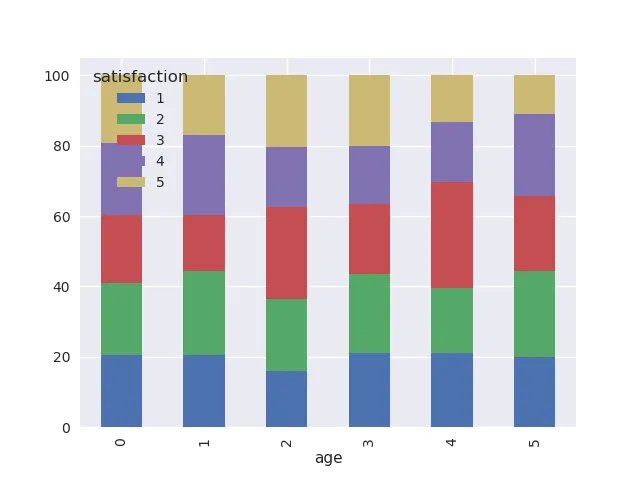 然而,如果要比较
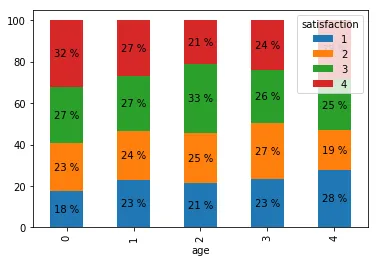
然而,如果要比较Age-0中green子集(百分比)是否高于Age-2中的子集,则会很困难。因此,有没有一种方法可以在每个条形图的子部分上方添加百分比。类似于这样,但是对于每个单独的条形图:
continue```- flashliquid