当我使用一个由75%'true'标签和25%'false'标签组成的不平衡数据集时,该如何设置libSVM中的gamma和Cost参数? 由于数据不平衡,我得到了所有预测标签都设为“True”的常数错误。
如果问题不在于libSVM,而是在于我的数据集,从理论机器学习的角度来看,我应该如何处理这种不平衡?*我使用的特征数量在4-10之间,数据点数量很少,只有250个。
如果问题不在于libSVM,而是在于我的数据集,从理论机器学习的角度来看,我应该如何处理这种不平衡?*我使用的特征数量在4-10之间,数据点数量很少,只有250个。
scikit-learn 包(建立在libsvm上)中有提供。C和gamma值。你应该尝试广泛的数值范围,对于C,选择1到10^15之间的值是合理的,而gamma的简单而好的启发式方法是计算所有数据点之间的成对距离,并根据此分布的百分位数选择gamma值。想象一下,在每个点中放置方差等于1/gamma的高斯分布——如果您选择了这样的gamma,那么这个分布将会与许多点重叠,从而得到非常“平滑”的模型,而使用小方差则会导致过拟合。C,因此即使它发生在幕后,类别平衡仍然与C的选择有关。 - Marc Claesengamma)等没有影响。最流行的两种方法是:C。通常是给较小的类分配更高的权重,一种常见的方法是npos * wpos = nneg * wneg。LIBSVM允许您使用其-wX标志来执行此操作。我知道这个问题已经被问过一段时间了,但我想回答一下,因为你可能会发现我的答案有用。
正如其他人提到的,你可能希望考虑为少数类使用不同权重或使用不同的误分类惩罚。然而,处理不平衡数据集的更聪明的方法是使用SMOTE(Synthetic Minority Over-sampling Technique)算法生成合成的少数类数据。这是一种可以很好地处理一些不平衡数据集的简单算法。
在算法的每次迭代中,SMOTE考虑两个随机的少数类实例,并在它们之间添加一个同类别的人造实例。该算法不断注入样本,直到两个类别平衡或达到其他某些标准(例如添加一定数量的实例)。下面你可以找到一个描述SMOTE算法在2D特征空间的简单数据集上所做的事情的图片。
将权重与少数类相关联是该算法的一种特殊情况。当你将权重$w_i$与实例i相关联时,实际上是在实例i之上添加额外的$w_i-1$个实例!
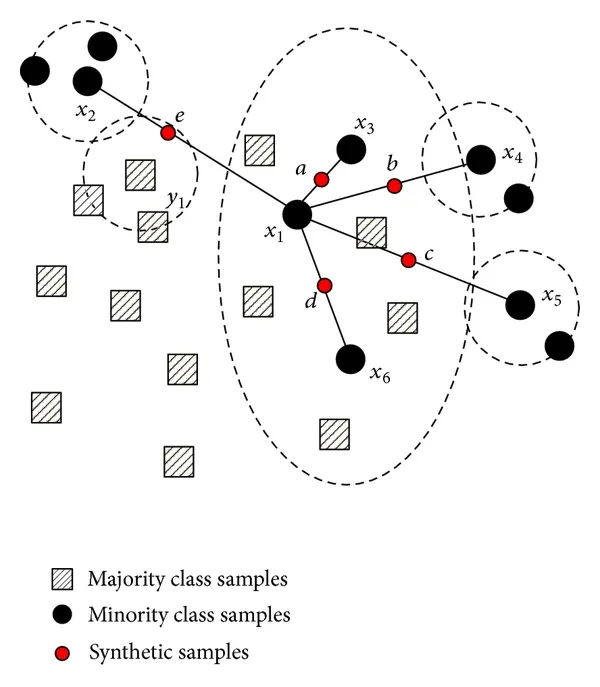
你需要做的是用该算法创建的样本增强你的初始数据集,并使用这个新的数据集训练SVM。你还可以在不同的编程语言中找到许多实现,例如Python和Matlab。
还有其他扩展这个算法的方式,如果你需要我可以指向更多材料。
要测试分类器,你需要将数据集分成测试集和训练集,在训练集中添加合成实例(请勿将其添加到测试集中),在训练集上训练模型,最后在测试集上进行测试。如果在测试时考虑生成的实例,你将得到一个偏斜的(和明显更高的)准确率和召回率。