我正在尝试使用人们在浏览横幅广告时点击和转化的数据来教授我的SVM算法。主要问题是,点击率仅占所有数据的0.2%,因此存在非常大的不均衡性。当我在测试阶段使用简单的SVM时,它总是预测“浏览”类别,而从不预测“点击”或“转化”。平均而言,它可以给出99.8%的正确答案(由于不均衡性),但如果你检查“点击”或“转化”的结果,它的正确预测率为0%。你如何调整SVM算法(或选择另一个算法)以考虑到这种不均衡性?
如何使用大不平衡类别数据教授机器学习算法?(SVM)
8
- rvnikita
3
提高少数类别的采样是一个选项吗? - Thomas Jungblut
你能详细说明一下什么是上采样吗? - rvnikita
可能是sklearn中处理不平衡类别的逻辑回归问题的重复问题。 - Fred Foo
2个回答
25
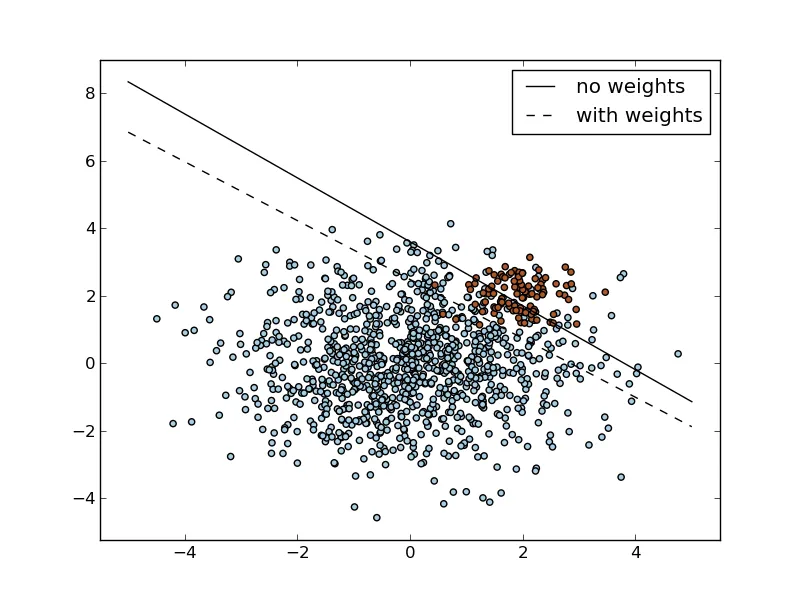
这里最基本的方法是使用所谓的“类别加权方案” - 在经典SVM公式中,有一个C参数用于控制误分类计数。它可以改变为分别用于1号和2号类的C1和C2参数。对于给定的C,最常见的选择是将C1和C2设置为
C1 = C / n1
C2 = C / n2
其中n1和n2分别是第1类和第2类的大小,因此你会"惩罚"SVM更严重地错误分类较不常见的类别,而不是错误分类最常见的类别。
许多现有的库(如libSVM)支持使用class_weight参数实现这种机制。
示例使用python和sklearn
print __doc__
import numpy as np
import pylab as pl
from sklearn import svm
# we create 40 separable points
rng = np.random.RandomState(0)
n_samples_1 = 1000
n_samples_2 = 100
X = np.r_[1.5 * rng.randn(n_samples_1, 2),
0.5 * rng.randn(n_samples_2, 2) + [2, 2]]
y = [0] * (n_samples_1) + [1] * (n_samples_2)
# fit the model and get the separating hyperplane
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X, y)
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-5, 5)
yy = a * xx - clf.intercept_[0] / w[1]
# get the separating hyperplane using weighted classes
wclf = svm.SVC(kernel='linear', class_weight={1: 10})
wclf.fit(X, y)
ww = wclf.coef_[0]
wa = -ww[0] / ww[1]
wyy = wa * xx - wclf.intercept_[0] / ww[1]
# plot separating hyperplanes and samples
h0 = pl.plot(xx, yy, 'k-', label='no weights')
h1 = pl.plot(xx, wyy, 'k--', label='with weights')
pl.scatter(X[:, 0], X[:, 1], c=y, cmap=pl.cm.Paired)
pl.legend()
pl.axis('tight')
pl.show()
特别地,在 sklearn 中,您可以通过设置 class_weight='auto' 来简单地启用自动加权。
- lejlot
2
非常感谢,这正是我所寻找的。我希望我有15个点来投票支持这个答案 :) - rvnikita
我非常确定你仍然可以勾选“接受答案”的选项 :) - lejlot
1
本文介绍了多种技术。其中一种简单但非常糟糕的SVM方法是仅复制少数类,直到实现平衡:
http://www.ele.uri.edu/faculty/he/PDFfiles/ImbalancedLearning.pdf
- denson
2
仅为完整性考虑 - 在SVM中,复制少数类永远不应该被使用。这相当于使用类权重,而同时在训练(和测试)时间方面完全低效。 - lejlot
我编辑了我的原始答案以反映lejlot的评论。 - denson
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接