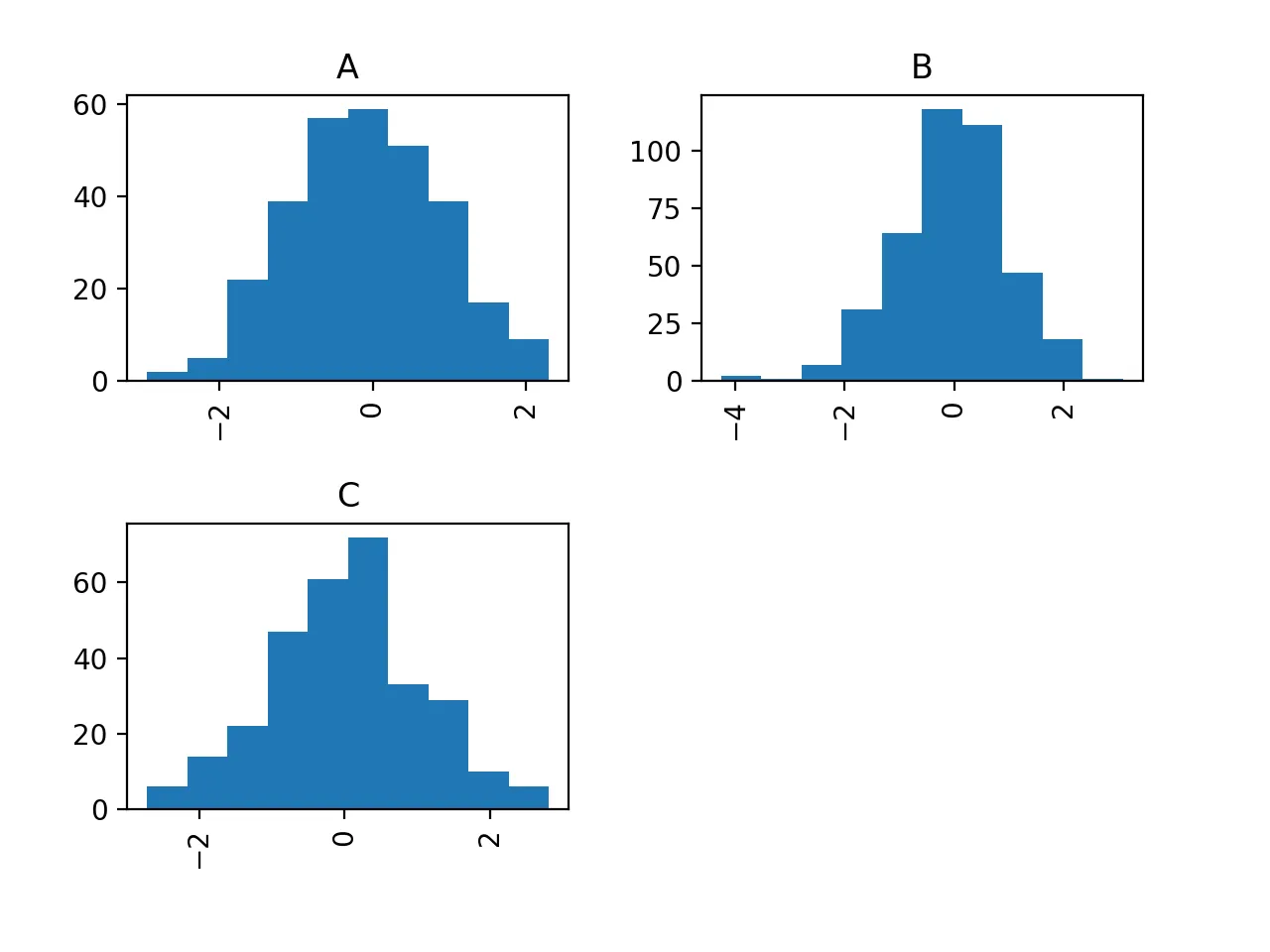
我正在进行得很顺利,刚刚发现了使用hist方法中的
by关键字来更简单地完成它的方法。
df.hist('N', by='Letter')
这是一个非常方便的小技巧,可以快速扫描您分组的数据!
对于未来的访问者,此调用的产品是以下图表:
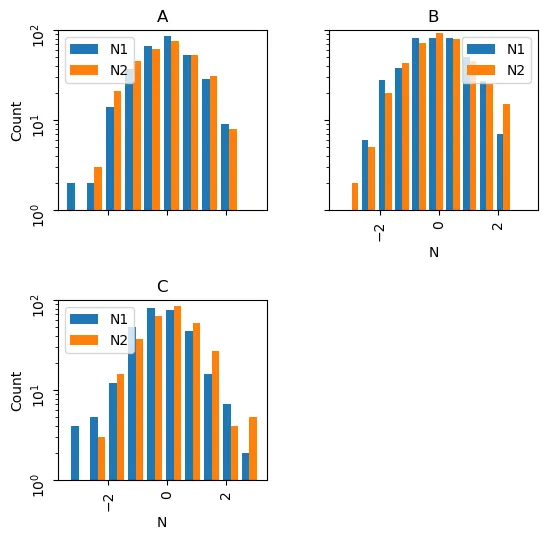
以下是对下面问题的回答,这里有一个直方图绘制的具体调整示例:
import pandas as pd
import numpy as np
x = ['A']*300 + ['B']*400 + ['C']*300
y = np.random.randn(1000)
z = np.random.randn(1000)
df = pd.DataFrame({'Letter':x, 'N1':y, 'N2':z})
axes = df.hist(['N1','N2'], by='Letter',bins=10, layout=(2,2),
legend=True, yrot=90,sharex=True,sharey=True,
log=True, figsize=(6,6))
for ax in axes.flatten():
ax.set_xlabel('N')
ax.set_ylabel('Count')
ax.set_ylim(bottom=1,top=100)