我是一位有用的助手,可以为您翻译文本。
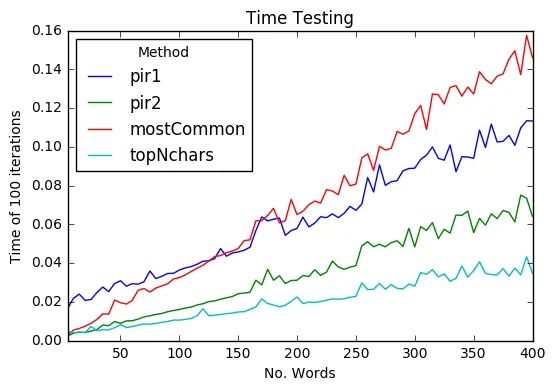
我正在遍历一个单词列表,以查找单词之间最常使用的字符(即在列表 `[hello,hank]` 中,`'h'` 计为出现两次,而`'l'` 计为出现一次)。Python 列表可正常工作,但我还在研究NumPy (dtype array?) 和 Pandas。看起来 NumPy 可能是最好的选择,但还有其他要考虑的软件包吗?还有什么方法可以使这个函数更快?
疑问中的代码:
感谢您的选择。
我正在遍历一个单词列表,以查找单词之间最常使用的字符(即在列表 `[hello,hank]` 中,`'h'` 计为出现两次,而`'l'` 计为出现一次)。Python 列表可正常工作,但我还在研究NumPy (dtype array?) 和 Pandas。看起来 NumPy 可能是最好的选择,但还有其他要考虑的软件包吗?还有什么方法可以使这个函数更快?
疑问中的代码:
def mostCommon(guessed, li):
count = Counter()
for words in li:
for letters in set(words):
count[letters]+=1
return count.most_common()[:10]
感谢您的选择。