编辑:事实证明正则表达式缓存对竞争有些不公平。我的错。正则表达式只比较快一点点。
如果你追求速度,hcwhsa的答案应该足够好了。如果你需要稍微更快一些,可以考虑使用re模块。
import re
from itertools import chain
lis = ['plu;ean;price;quantity'*1000, 'plu1;ean1;price1;quantity1'*100]*1000
matcher = re.compile('^(?:plu(?:;|$)|[^;]*;ean(?:;|$))').match
[l.split(';') for l in lis if matcher(l)]
时间安排,对于大多数积极的结果来说(也就是说,split 是减慢速度的主要原因):
SETUP="
import re
from itertools import chain
matcher = re.compile('^(?:plu(?:;|$)|[^;]*;ean(?:;|$))').match
lis = ['plu1;ean1;price1;quantity1'+chr(i) for i in range(10000)] + ['plu;ean;price;quantity' for i in range(10000)]
"
python -m timeit -s "$SETUP" "[[x] + [y] + z.split(';') for x, y, z in (item.split(';', 2) for item in lis) if x== 'plu' or y=='ean']"
python -m timeit -s "$SETUP" "[l.split(';') for l in lis if matcher(l)]"
我们看到我的速度稍微快一点。
10 loops, best of 3: 55 msec per loop
10 loops, best of 3: 49.5 msec per loop
对于大多数负面结果(大部分内容都被过滤):
SETUP="
import re
from itertools import chain
matcher = re.compile('^(?:plu(?:;|$)|[^;]*;ean(?:;|$))').match
lis = ['plu1;ean1;price1;quantity1'+chr(i) for i in range(1000)] + ['plu;ean;price;quantity' for i in range(10000)]
"
python -m timeit -s "$SETUP" "[[x] + [y] + z.split(';') for x, y, z in (item.split(';', 2) for item in lis) if x== 'plu' or y=='ean']"
python -m timeit -s "$SETUP" "[l.split(';') for l in lis if matcher(l)]"
引线稍微高一点。
10 loops, best of 3: 40.9 msec per loop
10 loops, best of 3: 35.7 msec per loop
如果结果始终唯一,请使用:
next([x] + [y] + z.split(';') for x, y, z in (item.split(';', 2) for item in lis) if x== 'plu' or y=='ean')
或者更快的正则表达式版本
next(filter(matcher, lis)).split(';')
(在Python 2中使用itertools.ifilter).
时间:
SETUP="
import re
from itertools import chain
matcher = re.compile('^(?:plu(?:;|$)|[^;]*;ean(?:;|$))').match
lis = ['plu1;ean1;price1;quantity1'+chr(i) for i in range(10000)] + ['plu;ean;price;quantity'] + ['plu1;ean1;price1;quantity1'+chr(i) for i in range(10000)]
"
python -m timeit -s "$SETUP" "[[x] + [y] + z.split(';') for x, y, z in (item.split(';', 2) for item in lis) if x== 'plu' or y=='ean']"
python -m timeit -s "$SETUP" "next([x] + [y] + z.split(';') for x, y, z in (item.split(';', 2) for item in lis) if x== 'plu' or y=='ean')"
python -m timeit -s "$SETUP" "[l.split(';') for l in lis if matcher(l)]"
python -m timeit -s "$SETUP" "next(filter(matcher, lis)).split(';')"
结果:
10 loops, best of 3: 31.3 msec per loop
100 loops, best of 3: 15.2 msec per loop
10 loops, best of 3: 28.8 msec per loop
100 loops, best of 3: 14.1 msec per loop
所以这对两种方法都有很大的提升。

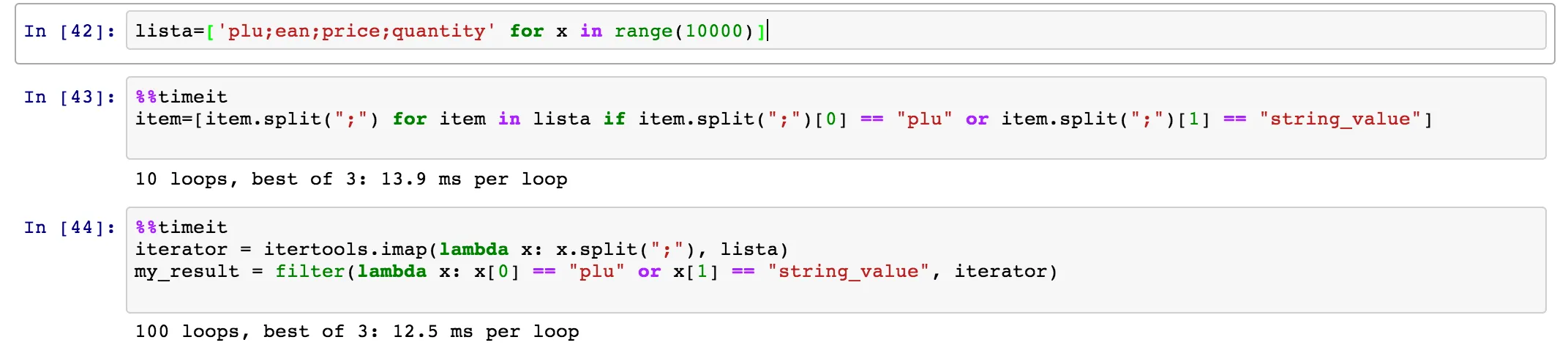
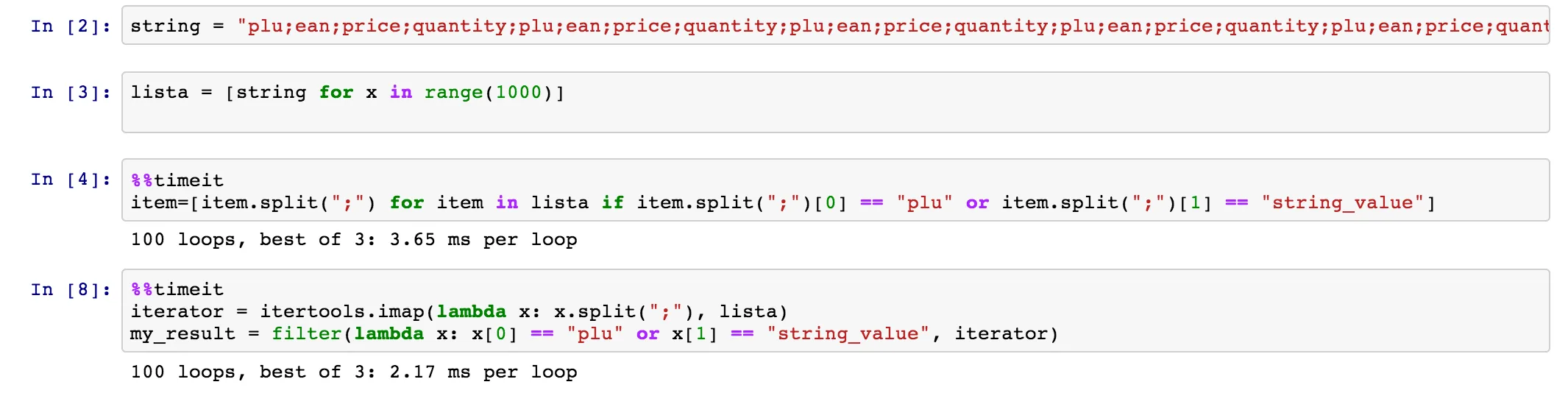
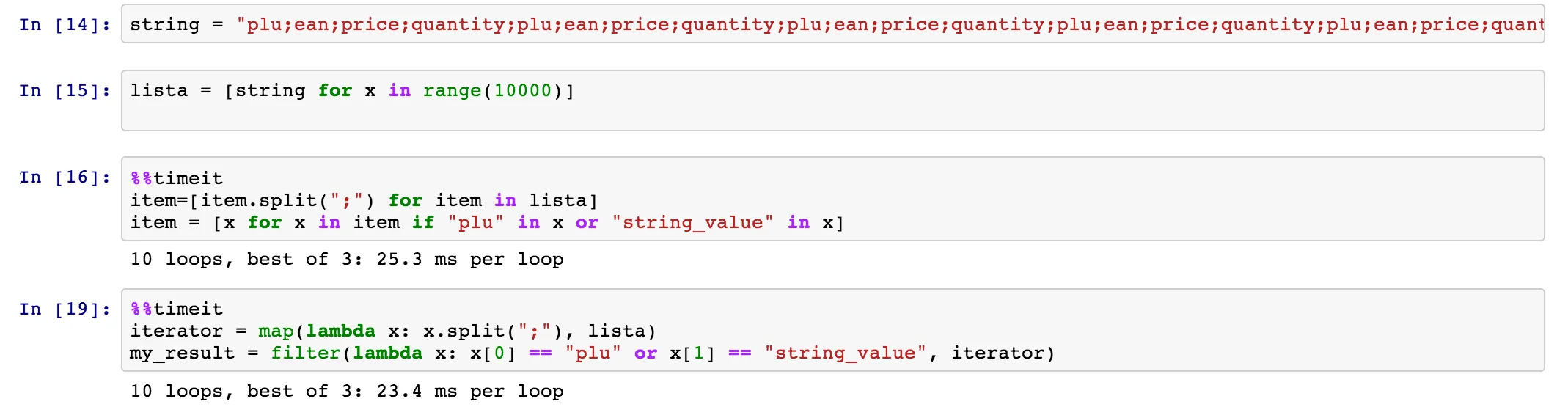
item.split(";")一次。在第二种情况下,您将调用item.split(";")三次。第二种情况肯定会更慢。 - wflynny