我正在使用以下代码在Python 2.7中运行lmfit拟合一些测试数据。我需要进行加权拟合,并使用1/y作为权重(使用Leven-Marq.算法)。我已经定义了权重并在此处使用:
from __future__ import division
from numpy import array, var
from lmfit import Model
from lmfit.models import GaussianModel, LinearModel
import matplotlib.pyplot as plt
import seaborn as sns
xd = array([1267, 1268, 1269, 1270, 1271, 1272, 1273, 1274, 1275, 1276,
1277, 1278, 1279, 1280, 1281, 1282, 1283, 1284, 1285, 1286, 1287, 1288,
1289, 1290, 1291, 1292, 1293, 1294, 1295, 1296, 1297, 1298, 1299, 1300,
1301, 1302, 1303, 1304, 1305, 1306, 1307, 1308, 1309, 1310, 1311, 1312,
1313, 1314, 1315, 1316, 1317, 1318, 1319, 1320, 1321, 1322, 1323, 1324,
1325, 1326, 1327, 1328, 1329, 1330, 1331, 1332, 1333, 1334])
yd = array([238, 262, 255, 271, 270, 281, 261, 278, 280, 254, 289, 285, 304, 314,
329, 342, 379, 450, 449, 564, 613, 705, 769, 899, 987, 1043, 1183, 1295, 1298,
1521, 1502, 1605, 1639, 1572, 1659, 1558, 1476, 1397, 1267, 1193, 1016, 951,
835, 741, 678, 558, 502, 480, 442, 399, 331, 334, 308, 283, 296, 265, 264,
273, 258, 270, 262, 263, 239, 263, 251, 246, 246, 234])
mod = GaussianModel() + LinearModel()
pars = mod.make_params(amplitude=25300, center=1299, sigma=7, slope=0, intercept=450)
result = mod.fit(yd, pars, method='leastsq', x=xd, weights=1./yd)
rsq = 1 - result.residual.var() / var(yd)
print(result.fit_report())
print rsq
plt.plot(xd, yd, 'bo', label='raw')
plt.plot(xd, result.init_fit, 'k--', label='Initial_Guess')
plt.plot(xd, result.best_fit, 'r-', label='Best')
plt.legend()
plt.show()
输出为:
[[Model]]
(Model(gaussian) + Model(linear))
[[Fit Statistics]]
# function evals = 27
# data points = 68
# variables = 5
chi-square = 0.099
reduced chi-square = 0.002
Akaike info crit = -434.115
Bayesian info crit = -423.017
[[Variables]]
sigma: 7.57360038 +/- 0.063715 (0.84%) (init= 7)
center: 1299.41410 +/- 0.071046 (0.01%) (init= 1299)
amplitude: 25369.3304 +/- 263.0961 (1.04%) (init= 25300)
slope: -0.15015228 +/- 0.071540 (47.65%) (init= 0)
intercept: 452.838215 +/- 93.28860 (20.60%) (init= 450)
fwhm: 17.8344656 +/- 0.150037 (0.84%) == '2.3548200*sigma'
height: 1336.33919 +/- 17.28192 (1.29%) == '0.3989423*amplitude/max(1.e-15, sigma)'
.
.
.
.
0.999999993313
在这里(或者紧接着 plt.plot(xd, yd, 'bo', label='raw') 之前)的最后一行是 R^2,生成的拟合结果附在这里 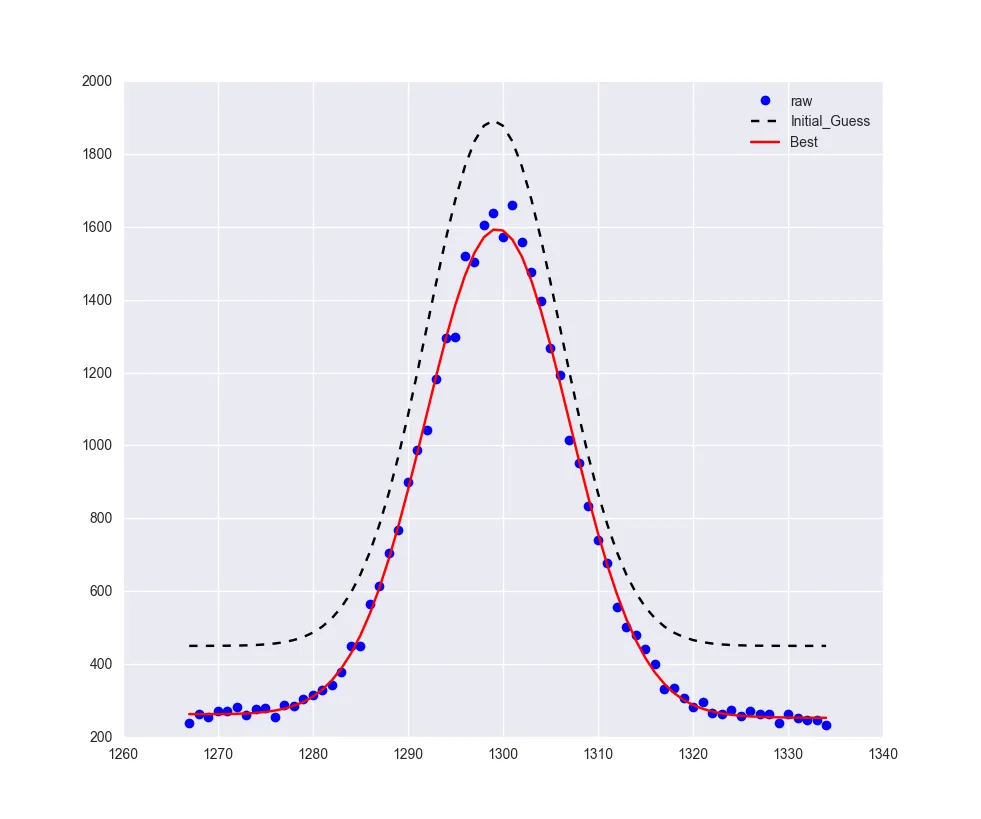 。
。
R^2 和输出的可视检查表明这是一个合理的拟合。我预计减小的卡方应该为 1.00 的量级(来源)。然而,返回的减小的卡方值比 1.00 小了几个数量级。
由于在 lmfit 中默认是 不使用权重,而我需要进行加权拟合,所以我定义了权重,但我认为我需要以不同的方式指定它们。我怀疑这种权重的规范可能导致减小的卡方值太小。
有没有其他方式来指定权重或其他参数,使得曲线拟合后的降低卡方接近或与1.00相同的数量级?
0.790。我尝试手动计算减少的卡方值,使用公式np.sum(((yd - result.best_fit)**2)/result.best_fit)/(68-5),得到了一个略微不同的值0.78065。我将点数设为68,拟合参数数目设为5(即问题中的约束数目),因此自由度数目为63。两者之间的差异几乎可以忽略不计...lmfit是否使用了稍微不同的方法来估计减少的卡方值? - edeszscale_covar=True时,例如振幅的参数误差更接近于从result.ci_report()报告的67.4%置信水平,而(b)scale_covar=False时,振幅的参数误差比result.ci_report()报告的67.4%置信水平要大得多。如果想要1 *sigma的参数不确定性,是否应该仅使用.ci_report()输出?有没有办法获得1sigma的.fit_report()不确定性? - edeszscale_covar的帖子以来,我仍在考虑它,并且我将在几天内提出一个单独的问题。至于这个关于加权和后续的问题,一切看起来都很好。没有更多问题了。再次感谢……非常有用的信息。 - edesz