这很容易使用
scipy.optimize.curve_fit(或者只是
scipy.optimize.leastsqr)来实现,内容涉及到IT技术。事实上,求和并不重要,也不重要你是否有参数数组。唯一需要注意的是,
curve_fit希望将参数作为单独的参数提供给拟合函数,而
leastsqr则提供一个单一向量。这里是一个解决方案:
import numpy as np
from scipy.optimize import curve_fit, leastsq
def f(x,r,s):
""" The fit function, applied to every x_k for the vectors r_i and s_i. """
x = x[...,np.newaxis]
x2s2 = (x*s)**2
return np.sum(r * x2s2 / (1 + x2s2), axis=-1)
popt,pcov = curve_fit(
lambda x,*params: f(x,params[:N],params[N:]),
X,Y,
np.r_[R0,S0],
)
R = popt[:N]
S = popt[N:]
popt,ier = leastsq(
lambda params: f(X,params[:N],params[N:]) - Y,
np.r_[R0,S0],
)
R = popt[:N]
S = popt[N:]
需要注意的几点:
- 开始时,我们需要适合于测量的1d数组
X和Y,初始猜测为1d数组R0和S0,N是这两个数组的长度。
- 我将实际模型
f的实现与提供给拟合器的目标函数分开。我使用lambda函数实现了这些目标函数。当然,也可以使用普通的def...函数并将它们组合成一个函数。
- 模型函数
f使用numpy的广播功能同时对一组参数进行求和(沿着最后一个轴),并且在许多x上并行计算(沿着最后一个轴之前的任何轴,尽管如果有多个轴...可以使用.ravel()来帮助解决)
- 我们使用numpy的简写
np.r_[R,S]将拟合参数R和S连接成单个参数向量。
curve_fit将每个单独的参数作为独立参数提供给目标函数。我们希望它们作为一个向量,因此我们使用*params:它将所有剩余的参数捕获到单个列表中。leastsq提供单个params向量。但是,它既不提供x,也不将其与y进行比较。它们直接绑定到目标函数中。
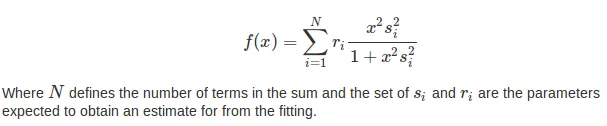 我打算将这样的函数拟合到我手头上的实验数据(x,y=f(x))。但是我有一些疑问:
我打算将这样的函数拟合到我手头上的实验数据(x,y=f(x))。但是我有一些疑问:
scipy.optimize.leastsq。 - Alan