我想要将单独的轴标签加粗。我知道@MrFlick的这个答案,但我不知道如何做到a)对多个项目进行操作,以及b)是否可以使用标签的名称而不是列表(或表达式)中的项目编号。
编辑(开始)
我也知道这个答案,但它基于填充美学(即a <- ifelse(data$category == 0, "red", "blue")来着色标签。这对我的情况不起作用,因为我不想根据填充美学来着色标签,而是想按照我喜欢的方式单独加粗它们。
编辑(结束)
这是一个示例数据集:
require(ggplot2)
require(dplyr)
set.seed(36)
xx<-data.frame(YEAR=rep(c("X","Y"), each=20),
CLONE=rep(c("A","B","C","D","E"), each=4, 2),
TREAT=rep(c("T1","T2","T3","C"), 10),
VALUE=sample(c(1:10), 40, replace=T))
然后我根据特定的因子组合对我的标签进行排序,然后在绘图的多个面板中应该保持这种排序。请参阅我之前的问题这里。
clone_order <- xx %>% subset(TREAT == "C" & YEAR == "X") %>%
arrange(-VALUE) %>% select(CLONE) %>% unlist()
xx <- xx %>% mutate(CLONE = factor(CLONE, levels = clone_order))
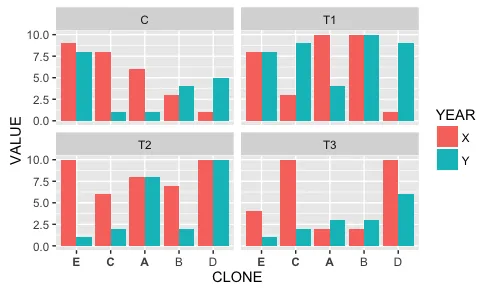
ggplot(xx, aes(x=CLONE, y=VALUE, fill=YEAR)) +
geom_bar(stat="identity", position="dodge") +
facet_wrap(~TREAT)
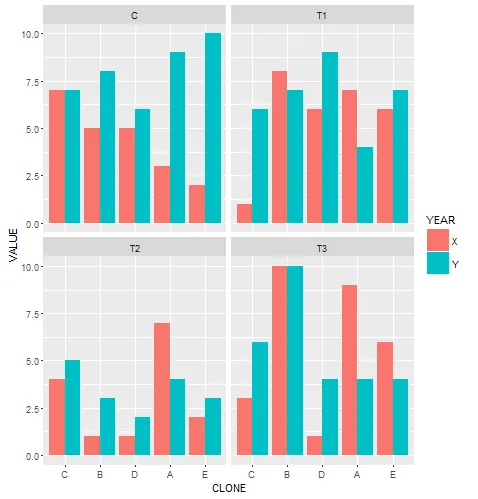
现在我想要加粗列表中的 Clone,A,B和E。我确信这样做肯定有办法,但我无法弄清楚如何操作。理想情况下,我们希望能够通过a)使用列表/表达式中的项目编号,以及b)通过使用标签(例如A,B和E)来实现。