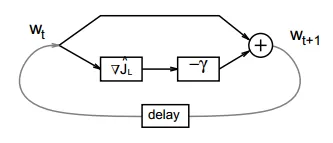
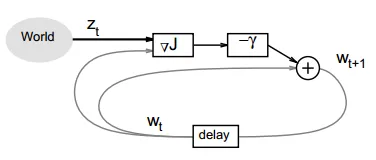
对于凸优化,例如逻辑回归。
例如我有100个训练样本。 在小批量梯度下降中,我将批量大小设置为10。
因此,在进行了10次小批量梯度下降更新后。 我可以通过一次梯度下降更新得到相同的结果吗? 对于非凸优化,例如神经网络。
我知道小批量梯度下降有时可以避免一些局部最优解。 但它们之间存在固定关系吗。
例如我有100个训练样本。 在小批量梯度下降中,我将批量大小设置为10。
因此,在进行了10次小批量梯度下降更新后。 我可以通过一次梯度下降更新得到相同的结果吗? 对于非凸优化,例如神经网络。
我知道小批量梯度下降有时可以避免一些局部最优解。 但它们之间存在固定关系吗。