我正在尝试编写一段代码,使用梯度下降法返回岭回归的参数。岭回归的定义如下:
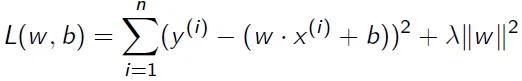
我应该实现的梯度下降算法如下:
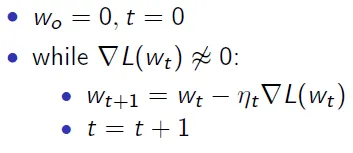
其中 ∇ 表示 L 关于 w 的梯度。η 是步长。t 是时间或迭代计数器。
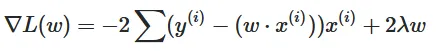
我的代码:
def ridge_regression_GD(x,y,C):
x=np.insert(x,0,1,axis=1) # adding a feature 1 to x at beggining nxd+1
w=np.zeros(len(x[0,:])) # d+1
t=0
eta=1
summ = np.zeros(1)
grad = np.zeros(1)
losses = np.array([0])
loss_stry = 0
while eta > 2**-30:
for i in range(0,len(y)): # here we calculate the summation for all rows for loss and gradient
summ=summ+((y[i,]-np.dot(w,x[i,]))*x[i,])
loss_stry=loss_stry+((y[i,]-np.dot(w,x[i,]))**2)
losses=np.insert(losses,len(losses),loss_stry+(C*np.dot(w,w)))
grad=((-2)*summ)+(np.dot((2*C),w))
eta=eta/2
w=w-(eta*grad)
t+=1
summ = np.zeros(1)
loss_stry = 0
b=w[0]
w=w[1:]
return w,b,losses
输出应该是截距参数b、向量w以及每次迭代的损失losses。
我的问题是,当我运行代码时,w和losses的值都在增加,都在10^13的数量级上。
如果您需要任何更多的信息或澄清,请随时询问。
注意:这篇文章已从Cross Validated论坛中删除。如果有更好的论坛可以发布,请告诉我。