使用从所需列构建的多级索引,可以高效地使用 isin 进行此操作:
df1 = pd.DataFrame({'c': ['A', 'A', 'B', 'C', 'C'],
'k': [1, 2, 2, 2, 2],
'l': ['a', 'b', 'a', 'a', 'd']})
df2 = pd.DataFrame({'c': ['A', 'C'],
'l': ['b', 'a']})
keys = list(df2.columns.values)
i1 = df1.set_index(keys).index
i2 = df2.set_index(keys).index
df1[~i1.isin(i2)]
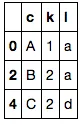
我认为这比@IanS的相似解决方案更好,因为它不假设任何列类型(即它适用于数字和字符串)。
(上面的答案是编辑的。以下是我的初始答案)
有趣! 这是我以前没有遇到过的...我可能会通过合并两个数组,然后删除定义了df2的行来解决它。这是一个示例,它使用了一个临时数组:
df1 = pd.DataFrame({'c': ['A', 'A', 'B', 'C', 'C'],
'k': [1, 2, 2, 2, 2],
'l': ['a', 'b', 'a', 'a', 'd']})
df2 = pd.DataFrame({'c': ['A', 'C'],
'l': ['b', 'a']})
df2['marker'] = 1
joined = pd.merge(df1, df2, on=['c', 'l'], how='left')
joined
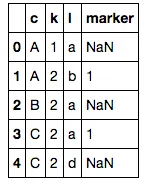
# extract desired columns where marker is NaN
joined[pd.isnull(joined['marker'])][df1.columns]
也许有一种方法可以不使用临时数组来完成这个操作,但我想不出来。只要你的数据不是非常庞大,上述方法应该是一个快速且足够的答案。