我有两个Pandas数据框,A和B。都有10列和索引'ID'。当A和B的ID匹配时,我想用A的行替换B的行。我尝试使用pd.update,但目前没有成功。非常感谢帮助。
3个回答
14
以下代码应该可以解决问题。
s1 = pd.Series([5, 1, 'a'])
s2 = pd.Series([6, 2, 'b'])
s3 = pd.Series([7, 3, 'd'])
s4 = pd.Series([8, 4, 'e'])
s5 = pd.Series([9, 5, 'f'])
df1 = pd.DataFrame([list(s1), list(s2),list(s3),list(s4),list(s5)], columns = ["A", "B", "C"])
s1 = pd.Series([5, 6, 'p'])
s2 = pd.Series([6, 7, 'q'])
s3 = pd.Series([7, 8, 'r'])
s4 = pd.Series([8, 9, 's'])
s5 = pd.Series([9, 10, 't'])
df2 = pd.DataFrame([list(s1), list(s2),list(s3),list(s4),list(s5)], columns = ["A", "B", "C"])
df1.loc[df1.A.isin(df2.A), ['B', 'C']] = df2[['B', 'C']]
print df1
输出
A B C
0 5 6 p
1 6 7 q
2 7 8 r
3 8 9 s
4 9 10 t
从评论中编辑:
要替换整行而不仅仅是一些列:
cols = list(df1.columns)
df1.loc[df1.A.isin(df2.A), cols] = df2[cols]
- Shijo
3
1老问题,但如果我想替换整行而不是某些列怎么办? - Rafael Almeida
@ Rafael Almeida 我假设你的两个数据框有相同的列集合;请尝试这个代码:cols = list(df1.columns) df1.loc[df1.A.isin(df2.A), cols] = df2[cols] - Shijo
最后一行代码
df1.loc[df1.A.isin(df2.A), ['B', 'C']] = df2[['B', 'C']] 对我来说产生了 NaN。我需要在赋值的值中添加 .values。它变成了 df1.loc[df1.A.isin(df2.A), ['B', 'C']] = df2[['B', 'C']].values。 - mahendri2
您可以通过将目标单元格设置为NaN来清空A中的内容,并使用
以下是一个示例,替换具有索引匹配的整行的内容:
combine_first()方法以填充B的值。尽管这听起来可能有些违反直觉,但这种方法可以让您在两行代码中同时针对行和特定列进行操作。希望这能帮到您。以下是一个示例,替换具有索引匹配的整行的内容:
# set-up
cols = ['c1','c2','c3']
A = pd.DataFrame(np.arange(9).reshape((3,3)), columns=cols)
B = pd.DataFrame(np.arange(10,16).reshape((2,3)), columns=cols)
#solution
A.loc[B.index] = np.nan
A = A.combine_first(B)
以下是仅替换具有索引匹配的行的某些目标列的示例:
A.loc[B.index, ['c2','c3']] = np.nan
A = A.combine_first(B)
- fpersyn
1
0
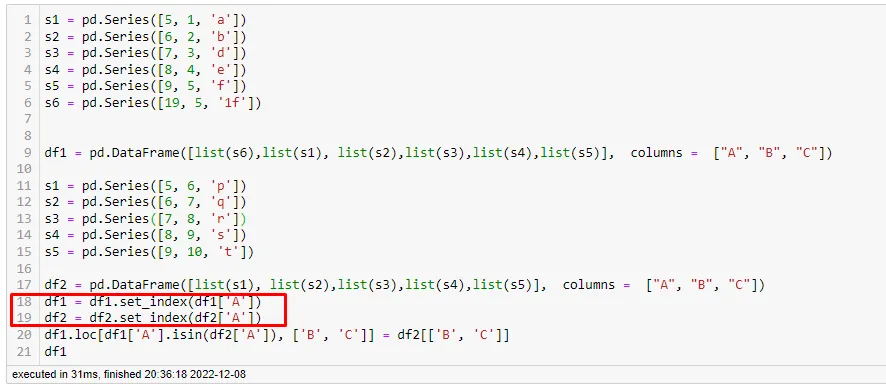 以上代码基于索引值运行。
如果两个数据框的行数不同,它将无法工作。
为此,我们需要将特定列设置为索引。
以上代码基于索引值运行。
如果两个数据框的行数不同,它将无法工作。
为此,我们需要将特定列设置为索引。
- Satish Khullar
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
A.combine_first(B)应该有效。请参考如何创建可重复的示例。 - shivsn