假设我有一些经验获得的数据:
from scipy import stats
size = 10000
x = 10 * stats.expon.rvs(size=size) + 0.2 * np.random.uniform(size=size)
它是指数分布(带有一些噪音),我想使用卡方适合度(GoF)测试来验证这一点。使用Python中的标准科学库(例如scipy或statsmodels)以最少的手动步骤和假设,最简单的方法是什么?
我可以使用以下模型进行拟合:
param = stats.expon.fit(x)
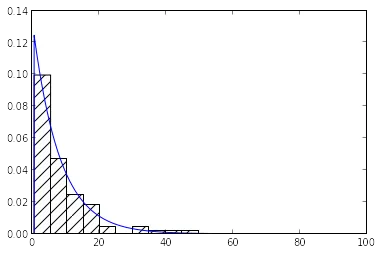
plt.hist(x, normed=True, color='white', hatch='/')
plt.plot(grid, distr.pdf(np.linspace(0, 100, 10000), *param))
计算Kolmogorov-Smirnov检验非常简洁。
>>> stats.kstest(x, lambda x : stats.expon.cdf(x, *param))
(0.0061000000000000004, 0.85077099515985011)
然而,我找不到一个好的方法来计算卡方检验。
statsmodel 中有一个离散分布的卡方拟合函数,但是指数分布是连续的,不能使用该函数。
official scipy.stats 教程 只讲解了自定义分布的情况,要通过调整许多表达式(npoints,npointsh,nbound,normbound)来构建概率分布,因此对我来说如何为其他分布进行计算并不很清楚。 chisquare 的示例 假设已经得到了期望值和自由度。
此外,我不想像这里讨论的那样“手动”执行测试,而是想知道如何应用其中一个可用的库函数。
anderson实现仅支持5种分布。 - metakermithstack并组合箱子以获得>5个数据点,但我不知道如何获取这些箱子的概率数组。我正在尝试找到一个通用的工作流程,可以用于任意数据,并且我不想像使用anderson实现时那样仅限于少数分布。 - metakermit