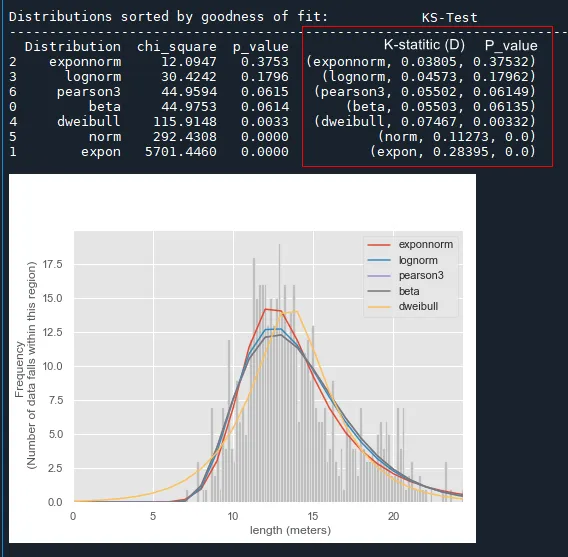
我正在尝试为我的数据找到最佳分布。 拟合如下图所示已完成,但我需要一种度量方法以选择最佳模型。 我使用卡方值比较拟合优度,并使用 Kolmogorov-Smirnov(KS)测试检验观察和拟合分布之间的显着差异。 我查找了一些潜在的解决方法1,2,3,但我没有得到答案。从下图的结果来看:
如果 p 值大于 k 统计值,则表示我们可以接受假设或数据很好地适合该分布吗?
另外,将显著性水平(a = 0.005)与 p 值进行比较,并决定是否接受或拒绝假设,这样做可以吗? 如果 p 值小于 a,则非常可能两个分布是不同的。
对于 Kolmogorov-Smirnov 测试,将数据标准化为(-1,1)是必要的吗?
从 KS 统计量和 p 值来看,exponnorm 最适合数据。对吗?
for distribution in dist_names:
# Set up distribution and get fitted distribution parameters
dist = getattr(scipy.stats, distribution)
param = dist.fit(y_std)
p = scipy.stats.kstest(y_std, distribution, args=param)[1]
p = np.around(p, 5)
p_values.append(p)
K统计量和K检验临界表中的临界值之间的比较。如果结果图中显示的K统计量值=0.0385,则K检验临界值表将为D_crit=1.36/sqrt(n)=> 0.0057?其中n=数据样本数。这样对吗?总样本数为569。 - Case Mseen大于50,所以使用D_crit=1.36/sqrt(n)而不是在临界值表中将显著性水平除以 n。 - NewcomerP_value=0,如图所示https://ibb.co/XzN4qhK。我不确定这是否正常,因为我得到了`K-static values`。 - Case Msee