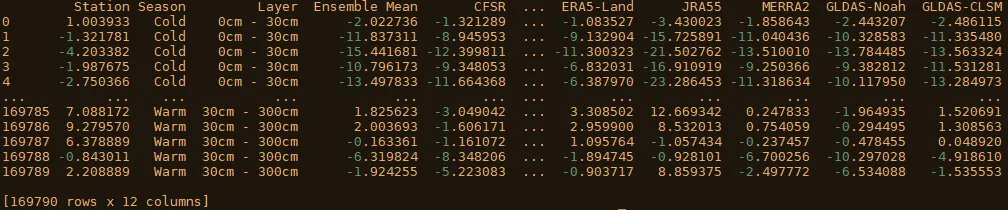
我有一个包含多个模型的土壤温度数据的数据框,我想创建一个散点矩阵。数据框如下:
数据按模型(或站点)组织,我还包括了一些列来区分数据出现在冷季还是暖季 ['Season'] ,以及数据来自哪个层 ['Layer']。
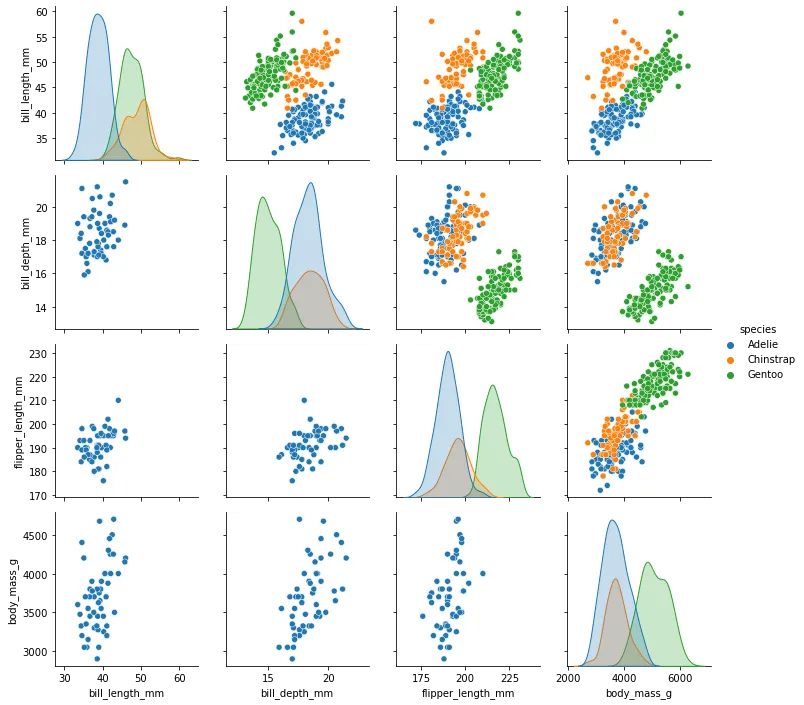
我的目标是创建以下特征的散点矩阵:
相关文件可以在这里找到: 以下是相关代码:
我的目标是创建以下特征的散点矩阵:
- 按季节着色的数据(到目前为止,我已在脚本中设置了这个)
- 底部三角仅由0cm到30cm土层的数据组成,上部三角仅由30cm到300cm土层的数据组成。
相关文件可以在这里找到: 以下是相关代码:
dframe_scatter_top = pd_read.csv(dframe_top.csv)
dframe_scatter_btm = pd_read.csv(dframe_btm.csv)
dframe_master = pd.read_csv(dframe_master.csv)
scatter1 = sn.pairplot(dframe_scatter_top,hue='Season',corner='True')
sns.set_context(rc={"axes.labelsize":20}, font_scale=1.0)
sns.set_context(rc={"legend.fontsize":18}, font_scale=1.0)
scatter1.set(xlim=(-40,40),ylim=(-40,40))
plt.show()
我认为诀窍在于使用PairGrid,并将数据的一部分设置为在地图上部出现,而将另一部分设置为在地图下部出现,但目前我没有看到明确拆分数据的方法。例如,或许可以通过以下方式实现:
scatter1 = sns.PairGrid(dframe_master)
scatter1.map_upper(#only plot data from 0-30cm)
scatter1.map_lower(#only plot data from 30-300cm)
{kind=link}
{kind=link}