sns.kdeplot:将shade_lowest替换为thresh,将shade替换为fill。但是,现在不再需要指定这些参数。sns.distplot已被sns.histplot替换。- 在
seaborn 0.12.0中测试通过。
import seaborn as sns
from sklearn.datasets import make_blobs
import numpy as np
n = 1000
X, y = make_blobs(n_samples=n, centers=3, n_features=3, random_state=0)
df2 = pd.DataFrame(data=np.hstack([X, y[np.newaxis].T]), columns=['X', 'Y', 'Z','model'])
df2['model'] = df2['model'].astype(str)
g = sns.PairGrid(df2, hue='model')
g.map_upper(plt.scatter)
g.map_lower(sns.kdeplot)
g.map_diag(sns.histplot, kde=True, stat='density', bins=20)
_ = g.add_legend()
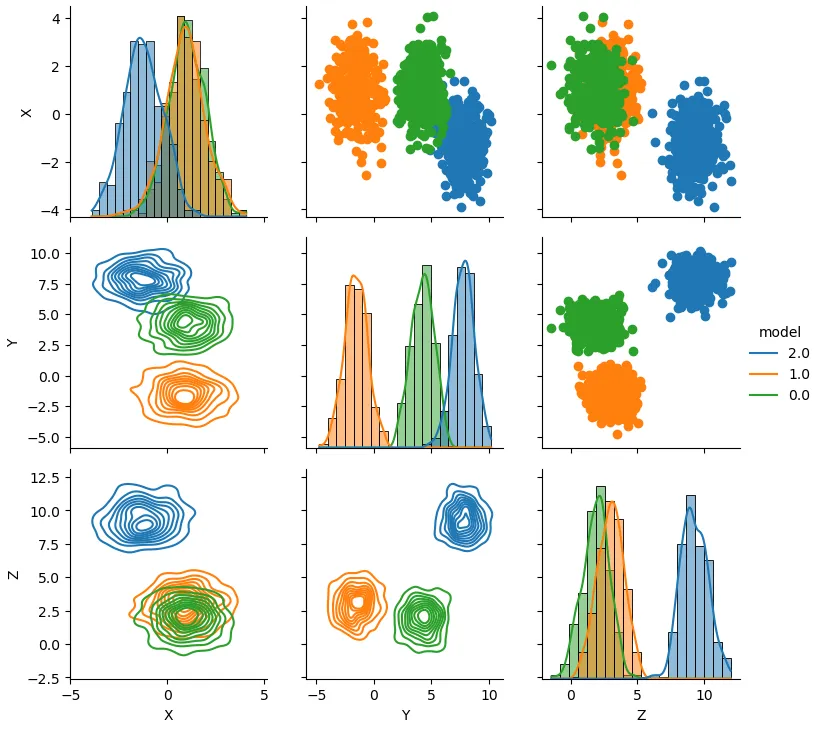
原始回答
我认为在PairGrid中使用要容易得多。
我在这里找到了一个很好的解释 Plotting on data-aware grids,因为PairGrid中的文档对我来说不够清晰。
您还可以让绘图的其他方面随hue变量的级别而变化,这有助于制作更易于在黑白打印时理解的图形。为此,请将字典传递给hue_kws,其中键是绘图函数关键字参数的名称,值是关键字值的列表,每个值都对应hue变量的一个级别。
本质上,是一个列表字典。关键字被传递到单个绘图函数中,其值来自其列表,每个值对应于您的变量的每个级别。请参见下面的代码示例。
我在分析中使用数字列作为hue,但它也应该在这里起作用。如果不行,您可以轻松地将“models”的每个唯一值映射到整数。
从
Martin Perez的好回答中借鉴,我会做如下处理:
编辑:完整的代码示例
编辑2:我发现kdeplot与数字标签不兼容。相应地更改了代码。
n = 1000
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=n, centers=3, n_features=3,random_state=0)
df2 = pd.DataFrame(data=np.hstack([X,y[np.newaxis].T]),columns=['X','Y','Z','model'])
df2['model'] = df2['model'].map('model_{}'.format)
list_of_cmaps=['Blues','Greens','Reds','Purples']
g = sns.PairGrid(df2,hue='model',
hue_kws={"cmap":list_of_cmaps},
)
g.map_upper(plt.scatter)
g.map_lower(sns.kdeplot,shade=True, shade_lowest=False)
g.map_diag(sns.distplot)
g.add_legend()
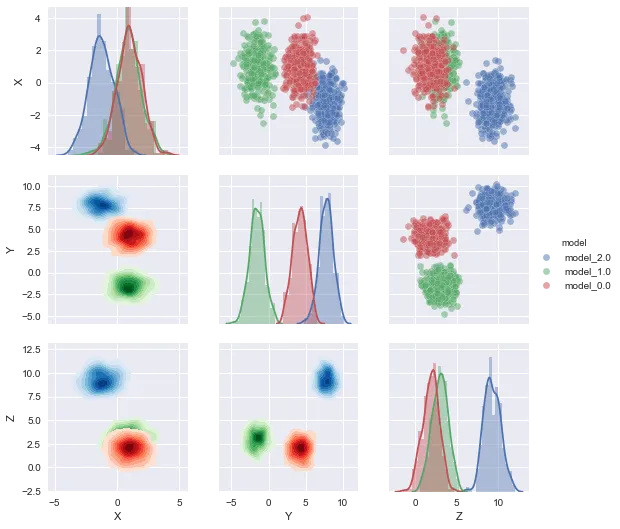
对于编程相关内容,您可以通过排序list_of_cmaps来为您的分类变量的特定级别分配特定阴影。
升级版是根据您需要的级别数量动态创建list_of_cmaps。
kdeplot编写一个小的包装函数,使其能够理解双变量图中的“颜色”参数,并使用它来选择适当的颜色映射,例如使用sns.dark_palette。等我有时间时,我会做一个例子,但这可能会有所帮助。 - mwaskom