我想要将一些数据使用指数函数进行拟合。我使用了
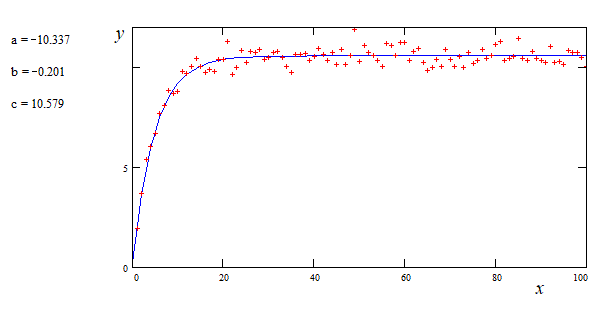
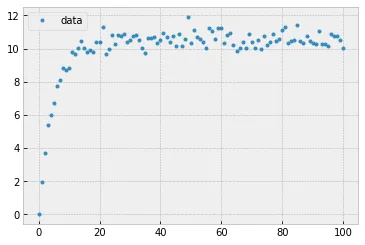
下面是数据的图像: data.png 从图中可以看出,数据似乎遵循指数规律。
问题在于curve_fit()返回的系数a、b和c很大或很小,而实际上应该返回类似于
scipy.optimize.curve_fit,因为我已经在其他的拟合中使用过它。但这次出现了问题,我无法弄清楚问题所在。下面是数据的图像: data.png 从图中可以看出,数据似乎遵循指数规律。
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
data = np.array([
0., 1.93468444, 3.69735865, 5.38185988, 6.02549022,
6.69199075, 7.72316694, 8.08913061, 8.84570241, 8.69711608,
8.80038144, 9.78951087, 9.68486674, 10.06175145, 10.44039495,
10.0481156 , 9.76656204, 9.88581457, 9.81805445, 10.42432252,
10.41102239, 11.2911395 , 9.64866184, 9.98072231, 10.83644694,
10.24748571, 10.81333209, 10.75949899, 10.90367328, 10.42446764,
10.51441017, 10.73047737, 10.8159758 , 10.51013538, 10.02862504,
9.76352112, 10.64829309, 10.6293347 , 10.67752596, 10.34801542,
10.53158576, 10.92883362, 10.67002314, 10.37015825, 10.74876349,
10.12821343, 10.8974205 , 10.1591103 , 10.588377 , 11.92134556,
10.309095 , 11.1174362 , 10.72654524, 10.60890374, 10.37456491,
10.05935346, 11.21295863, 11.09013951, 10.60862773, 11.2558922 ,
11.24660234, 10.35981557, 10.81284365, 10.96113067, 10.22716439,
9.8394873 , 10.01892084, 10.38237311, 10.04920671, 10.87782442,
10.42438756, 10.05614503, 10.5446946 , 9.99974368, 10.76930547,
10.22164072, 10.36942999, 10.89888302, 10.47035428, 10.58157374,
11.12615892, 11.30866718, 10.33215937, 10.46723351, 10.54072701,
11.45027197, 10.45895588, 10.34176601, 10.78405493, 10.43964778,
10.34047484, 10.25099046, 11.05847515, 10.27408195, 10.27529163,
10.16568845, 10.86451738, 10.73205291, 10.73300649, 10.49463959,
10.03729782
])
t = np.linspace(0, 100, len(data)) #time array
def expo(x, a, b, c): #exponential function for fitting
return a * np.exp(b * x) + c
fig1, ax1 = plt.subplots()
ax1.plot(t, data, ".", label="data")
coefs = curve_fit(expo, t, data)[0] # fitting
ax1.plot(t, expo(t, coefs[0], coefs[1], coefs[2]), "-", label="fit")
ax1.legend()
plt.show()
问题在于curve_fit()返回的系数a、b和c很大或很小,而实际上应该返回类似于
a = -10.5, b = -0.2, c = 10.5 这样的结果。
{kind=link}
curve_fit可能会在非线性拟合时失败,以至于我已经停止计数(实际上甚至没有开始)。简单的搜索会更快、更容易、更经济。 - mikuszefski