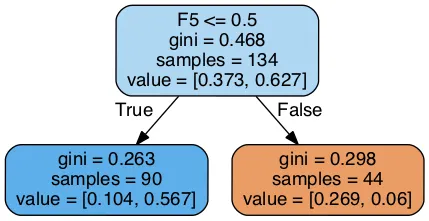
针对上图,我使用了来自scipy和graphviz的AdaBoostClassifier库,创建了这个子树可视化图,我需要帮助解释每个节点中的值。比如,“gini”是什么意思?“samples”和“value”字段的含义是什么?属性F5 <= 0.5是什么意思?
以下是我的代码(我全部在jupyter notebook中完成):
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
f = open('dtree-data.txt')
d = dict()
for i in range(1,9):
key = 'F' + str(i)
d[key] = []
d['RES'] = []
for line in f:
values = [(True if x == 'True' else False) for x in line.split()[:8]]
result = line.split()[8]
d['RES'].append(result)
for i in range(1, 9):
key = 'F' + str(i)
d[key].append(values[i-1])
df = pd.DataFrame(data=d, columns=['F1','F2','F3','F4','F5','F6','F7','F8','RES'])
from sklearn.model_selection import train_test_split
X = df.drop('RES', axis=1)
y = df['RES']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
from IPython.display import Image
from sklearn.externals.six import StringIO
from sklearn.tree import export_graphviz
import pydot
# https://dev59.com/jlYO5IYBdhLWcg3wMO1y
sub_tree = ada.estimators_[0]
dot_data = StringIO()
features = list(df.columns[1:])
export_graphviz(sub_tree, out_file=dot_data,feature_names=features,filled=True,rounded=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph[0].create_png())
注意:为了能够在本地查看数据,可能需要安装外部程序包。 这是数据文件的链接: https://cs.rit.edu/~jro/courses/intelSys/dtree-data