2个回答
5
DecisionTreeClassifier:
DecisionTreeClassifier中的value是每个节点samples的类别分割。
请注意,如果在调用fit()时加权了类,则value可能也会被加权。
例如:
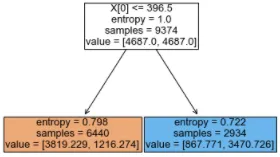
cw={0: 0.6495288248337029, 1: 2.1719184430027805}
拿到真节点后,计算您的真实类别分裂如下:
>>> [3819.229 / cw[0], 1216.274 / cw[1]]
[5880, 560]
如果不清楚的话,您的标准是基于加权分割计算的:
>>> a, b = 3819.229, 1216.274
>>> ab = a + b
>>> (-(a / ab)*math.log2(a / ab)) - ((b / ab)*math.log2(b / ab))
0.7975914228753467
DecisionTreeRegressor:
DecisionTreeRegressor中的value是指该节点对于一个新样本预测的值。如果你的评价标准是均方误差(MSE),你会发现value是该节点中样本的平均测量值。
例如:
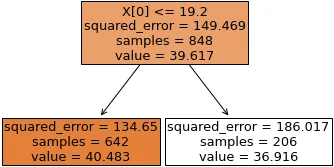
*(数据:Seaborn的“dots”示例集。)
拟合在相干性上预测发射率的深度1回归树。它不是非常有用的树,但它说明了这个想法。
对于当前节点, value的计算方式为:
>>> value = data[data.coherence <= 19.2].firing_rate.mean()
>>> value
40.48326118418657
该节点的平方误差为:
squared_error
>>> ((data[data.coherence <= 19.2].firing_rate - value)**2).mean()
134.6504380931471
- snzai
2
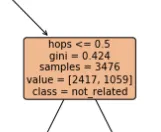
他们正在向您指示步骤中每个类别的样本数量。例如,您的图片显示在“hops<=5”之前的分裂之前,您有2417个类0的样本和1059个类1的样本。请注意,如果您将这两个值相加,您将得到与参数“samples”相同的数字(3476)。如果树运行成功,您将观察到数据在每个步骤中的分裂情况越来越好。对于最终的叶节点,您将看到明确的值,例如
[300, 2]。然后,您可以说所有这些样本都是类0。- Alex Serra Marrugat
2
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
DecisionTreeRegressor中,特别是对于内部节点,你有什么想法它的含义是什么? - zyxue