在`sklearn.linear_model.LogisticRegression`中,
C参数的含义是什么?它如何影响决策边界?高值的C是否会使决策边界变得非线性?如果我们可视化决策边界,逻辑回归的过拟合会呈现怎样的特征?C参数的含义是什么?它如何影响决策边界?高值的C是否会使决策边界变得非线性?如果我们可视化决策边界,逻辑回归的过拟合会呈现怎样的特征?来自文档:
C: 浮点数,默认值为1.0。 正则化强度的倒数;必须是一个正浮点数。与支持向量机类似,较小的值指定了更强的正则化。
如果你不理解这个,可以在Cross Validated上询问比在这里好。
尽管计算机科学人员经常把函数的所有参数都称为“参数”,但在机器学习中,C被称为“超参数”。参数是告诉模型如何处理特征的数字,而超参数告诉模型如何选择参数。
正则化通常指更极端的参数应该有复杂度惩罚的概念。这个想法是,只看训练数据而不关注参数的极端程度会导致过度拟合。C的高值告诉模型要给予训练数据更高的权重,而对复杂度惩罚给予较低的权重。低值告诉模型要更多地考虑复杂度惩罚,以代价适配训练数据。基本上,高C意味着“非常相信这些训练数据”,而低值表示“这些数据可能不能完全代表真实世界数据,所以如果它让你使参数非常大,就不要听它的”。
scores = X.dot(coefficients) + intercept
log_likelihood = np.sum((y-1)*scores - np.log(1 + np.exp(-scores)))
penalty_term = (1 / C if C else 0) * np.sum(coefficients**2) # only regularize non-intercept coefficients
log_likelihood = np.sum((y-1)*scores - np.log(1 + np.exp(-scores))) - penalty_term
# ^^^^^^^^^^^^^^ <--- penalty here
from sklearn.datasets import make_classification
import numpy as np
def logistic_regression(X, y, C=None, step_size=0.005):
coef_ = np.array([0.]*X.shape[1])
l2_penalty = 1 / C if C else 0
for ctr in range(100):
# predict P(y_i = 1 | X_i, coef_)
predicted_proba = 1 / (1 + np.exp(-X.dot(coef_)))
errors = y - predicted_proba
# add penalty only for non-intercept
penalty = 2*l2_penalty*coef_*[0, *[1]*(len(coef_)-1)]
# compute derivatives and add penalty
derivatives = X.T.dot(errors) - penalty
# update the coefficients
coef_ += step_size * derivatives
return coef_
def log_likelihood(X, y, coef_, C=None):
penalty_term = (1 / C if C else 0) * np.sum(coef_[1:]**2)
scores = X.dot(coef_)
return np.sum((y-1)*scores - np.log(1 + np.exp(-scores))) - penalty_term
def compute_accuracy(X, y, coef_):
predictions = (X.dot(coef_) > 0)
return np.mean(predictions == y)
# example
X, y = make_classification()
X_ = np.c_[[1]*100, X]
coefs = logistic_regression(X_, y, C=0.01)
accuracy = compute_accuracy(X_, y, coefs)
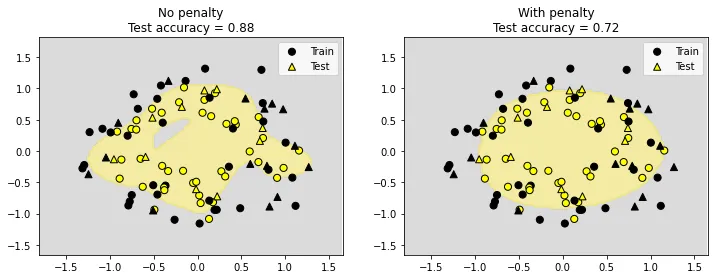
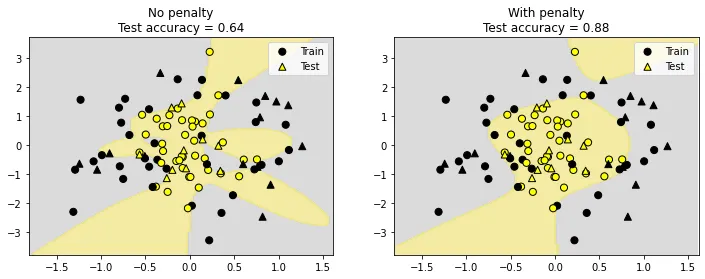
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression
from matplotlib.colors import ListedColormap
def plot_class_regions(clf, transformer, X, y, ax=None):
if ax is None:
fig, ax = plt.subplots(figsize=(6,6))
# lighter cmap for contour filling and darker cmap for markers
cmap_light = ListedColormap(['lightgray', 'khaki'])
cmap_bold = ListedColormap(['black', 'yellow'])
# create a sample for contour plot
x_min, x_max = X[:, 0].min()-0.5, X[:, 0].max()+0.5
y_min, y_max = X[:, 1].min()-0.5, X[:, 1].max()+0.5
x2, y2 = np.meshgrid(np.arange(x_min, x_max, 0.03), np.arange(y_min, y_max, 0.03))
# transform sample
sample = np.c_[x2.ravel(), y2.ravel()]
if transformer:
sample = transformer.transform(sample)
# make predictions
preds = clf.predict(sample).reshape(x2.shape)
# plot contour
ax.contourf(x2, y2, preds, cmap=cmap_light, alpha=0.8)
# scatter plot
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, s=50, edgecolor='black', label='Train')
ax.set(xlim=(x_min, x_max), ylim=(y_min, y_max))
return ax
def plotter(X, y):
# train-test-split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# add more features
poly = PolynomialFeatures(degree=6)
X_poly = poly.fit_transform(X_train)
fig, axs = plt.subplots(1, 2, figsize=(12,4), facecolor='white')
for i, lr in enumerate([LogisticRegression(penalty=None, max_iter=10000),
LogisticRegression(max_iter=2000)]):
lr.fit(X_poly, y_train)
plot_class_regions(lr, poly, X_train, y_train, axs[i])
axs[i].scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=ListedColormap(['black', 'yellow']),
s=50, marker='^', edgecolor='black', label='Test')
axs[i].set_title(f"{'No' if i == 0 else 'With'} penalty\nTest accuracy = {lr.score(poly.transform(X_test), y_test)}")
axs[i].legend()
# not overfit -- no need for regularization
X, y = make_circles(factor=0.7, noise=0.2, random_state=2023)
plotter(X, y)
# overfit -- needs regularization
X, y = make_circles(factor=0.3, noise=0.2, random_state=2023)
X[:, 1] += np.random.default_rng(2023).normal(size=len(X))
plotter(X, y)
C参数的含义是什么)。我关心的是可视化部分(即它如何影响决策边界的形状)。我希望有人能提供一个带有可视化示例的例子。 - Abdulwahab Almestekawy