在一句话中,正则化使模型在训练数据上表现更差,以便在保留数据上表现更好。
逻辑回归是一个优化问题,其中最小化以下目标函数。
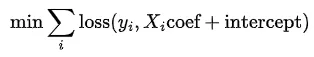
在使用
solver='lbfgs'时,损失函数看起来至少如下所示。

正则化将系数的范数添加到该函数中。以下实现了L2惩罚。
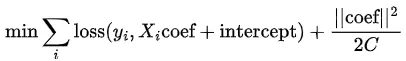
从方程中可以看出,正则化项的作用是惩罚大的系数(最小化问题是为了找到使目标函数最小化的系数)。由于每个系数的大小取决于其对应变量的尺度,因此需要对数据进行缩放,以便正则化项平等地惩罚每个变量。正则化强度由
C确定,随着C的增加,正则化项变小(对于极大的C值,几乎没有正则化)。
如果初始模型过拟合(即,它在训练数据上拟合得太好),那么添加一个强正则化项(使用较小的
C值)会使模型在训练数据上表现更差,但引入这种“噪声”会提高模型在未见过的(或测试)数据上的性能。
下面展示了具有1000个样本和200个特征的示例。从在不同的C值上准确率的图表中可以看出,如果C很大(几乎没有正则化),模型在训练数据和测试数据上的表现存在很大差距。然而,当C减小时,模型在训练数据上表现较差,但在测试数据上表现更好(测试准确率增加)。然而,当C变得太小(或正则化变得过强)时,模型再次开始表现较差,因为现在正则化项完全主导目标函数。
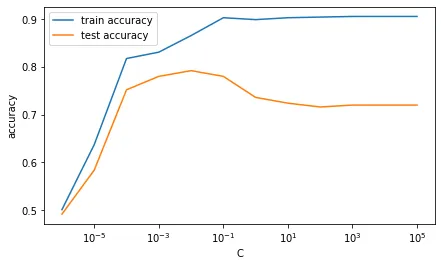
用于生成图表的代码:
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
X, y = make_classification(1000, 200, n_informative=195, random_state=2023)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2023)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
scores = {}
for C in (10**k for k in range(-6, 6)):
lr = LogisticRegression(C=C)
lr.fit(X_train, y_train)
scores[C] = {'train accuracy': lr.score(X_train, y_train),
'test accuracy': lr.score(X_test, y_test)}
pd.DataFrame.from_dict(scores, 'index').plot(logx=True, xlabel='C', ylabel='accuracy');