我有一个模型方程,我们称之为eq_m:
然而,由于eq_m是非线性的,因此我使用了scipy的curve_fit来获取lambda、mu和sigma参数值,使用以下代码段:
我在各种数据组上运行这个模型,它们都应该遵循这个模型,其中55/60给我很好的结果,然而另外的5个组被高度过度拟合,并且预测参数具有很高的正值。是否有一种方法可以使用scipy/numpy或scikit-learn来压缩曲线拟合并惩罚高幅度参数值?
我的主管建议使用共轭先验分布,但我不知道如何在这里做到这一点。
请问有谁能帮助我解决这个问题吗?如果我要提供一个猜测来解决这个问题,有人能告诉我如何计算这些猜测吗?
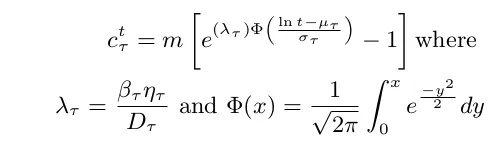
然而,由于eq_m是非线性的,因此我使用了scipy的curve_fit来获取lambda、mu和sigma参数值,使用以下代码段:
opt_parms, parm_cov = o.curve_fit(eq_m, x, y,maxfev=50000)
lamb , mu, sigm = opt_parms
我在各种数据组上运行这个模型,它们都应该遵循这个模型,其中55/60给我很好的结果,然而另外的5个组被高度过度拟合,并且预测参数具有很高的正值。是否有一种方法可以使用scipy/numpy或scikit-learn来压缩曲线拟合并惩罚高幅度参数值?
我的主管建议使用共轭先验分布,但我不知道如何在这里做到这一点。
请问有谁能帮助我解决这个问题吗?如果我要提供一个猜测来解决这个问题,有人能告诉我如何计算这些猜测吗?