你可以使用
np.linalg.lstsq并手动构建系数矩阵。首先,我将创建示例数据
x和
y,以及“完美拟合”
y0:
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(100)
y0 = 0.07 * x ** 3 + 0.3 * x ** 2 + 1.1 * x
y = y0 + 1000 * np.random.randn(x.shape[0])
现在我将创建一个完整的三次多项式“训练”或“自变量”矩阵,其中包括常数d列。
XX = np.vstack((x ** 3, x ** 2, x, np.ones_like(x))).T
让我们看一下使用这个数据集进行拟合并将其与 polyfit 进行比较时得到的结果:
p_all = np.linalg.lstsq(X_, y)[0]
pp = np.polyfit(x, y, 3)
print np.isclose(pp, p_all).all()
我使用了np.isclose,因为这两个算法确实存在非常小的差异。
你可能会想:'很好,但我还是没有回答问题。从这里开始,强制拟合具有零偏移量与从数组中删除np.ones列是相同的:
p_no_offset = np.linalg.lstsq(XX[:, :-1], y)[0]
好的,让我们看一下这个拟合与我们的数据相比如何:
y_fit = np.dot(p_no_offset, XX[:, :-1].T)
plt.plot(x, y0, 'k-', linewidth=3)
plt.plot(x, y_fit, 'y--', linewidth=2)
plt.plot(x, y, 'r.', ms=5)
这将得到以下这个图形:
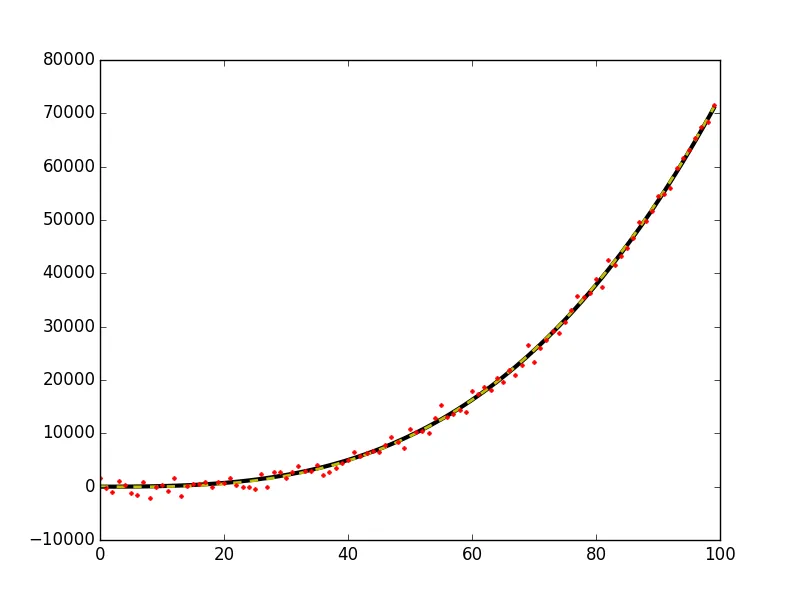
警告:如果您在数据上使用此方法,而数据实际上没有通过(x,y)=(0,0),您的输出解决方案系数(p)的估计值将会
偏差,因为
lstsq将试图弥补您的数据中存在偏移量的事实。有点像一个“圆孔方木”的问题。
此外,您还可以通过执行以下操作将数据仅拟合为立方体函数:
p_ = np.linalg.lstsq(X_[:1, :], y)[0]
再次提醒,如果您的数据包含二次、一次或常数项,则
三次系数的估计值将存在偏差。在数值算法中,有时候这种情况是有用的,但对于
统计学目的而言,包括所有较低阶段是非常重要的。如果测试结果显示低阶项与零没有统计学上的显著差异,那么就没问题了,但为了安全起见,在估计三次项时最好将它们保留。
祝您好运!
np.isclose,在其他情境下也可能对我有用。 - uday