我有从机器(m1,m2等)记录的信号,共28天。 (注意:每天的每个信号长度为360)。
machine_num, day1, day2, ..., day28
m1, [12, 10, 5, 6, ...], [78, 85, 32, 12, ...], ..., [12, 12, 12, 12, ...]
m2, [2, 0, 5, 6, ...], [8, 5, 32, 12, ...], ..., [1, 1, 12, 12, ...]
...
m2000, [1, 1, 5, 6, ...], [79, 86, 3, 1, ...], ..., [1, 1, 12, 12, ...]
我希望能够预测每台机器未来三天的信号序列,即在
day29、day30和day31。然而,我没有day29、day30和day31的数值。所以,我的计划是使用LSTM模型。第一步是获取day1的信号并预测day2的信号,然后在下一步中获取day1和day2的信号并预测day3的信号,以此类推,直到达到day28时,网络拥有所有信号并被要求预测day29等的信号。我尝试了如下的单变量LSTM模型。# univariate lstm example
from numpy import array
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
# define dataset
X = array([[10, 20, 30], [20, 30, 40], [30, 40, 50], [40, 50, 60]])
y = array([40, 50, 60, 70])
# reshape from [samples, timesteps] into [samples, timesteps, features]
X = X.reshape((X.shape[0], X.shape[1], 1))
# define model
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(3, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# fit model
model.fit(X, y, epochs=1000, verbose=0)
# demonstrate prediction
x_input = array([50, 60, 70])
x_input = x_input.reshape((1, 3, 1))
yhat = model.predict(x_input, verbose=0)
print(yhat)
然而,这个示例非常简单,因为它没有像我的一样的长序列。例如,对于
m1的数据如下所示。m1 = [[12, 10, 5, 6, ...], [78, 85, 32, 12, ...], ..., [12, 12, 12, 12, ...]]
此外,我需要第29、30、31天的预测。在这种情况下,我不确定如何更改此示例以满足我的需求。我想具体知道我选择的方向是否正确。如果是的话,该如何操作。
如果需要,我很乐意提供更多细节。
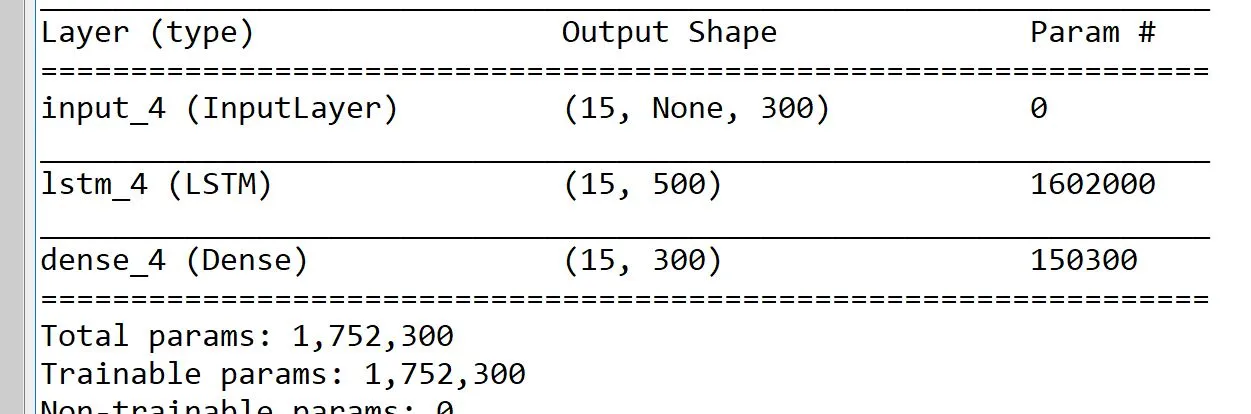
编辑:我已经提到了model.summary()。