我需要大家的帮助。
实际上,我想要预测变量Y(c_start)的下一个值,当X(day)表示时间时。
如您在图片中所见,我有属性“c_start”的值,并且我想要预测未来7天(例如)的下一个“c_start”值。
可以有人帮我吗?
谢谢大家!
使用Python进行时间序列预测
4
- issouluch
14
请发布原始输入数据,编写您的代码和期望输出,而不是图像。 - EdChum
你可以在第一张图片中看到原始输入数据。 - issouluch
@issouluch 需要一个原始的 CSV 数据文件。您可以使用 Dropbox 共享链接或 Google Driver 上传它。 - Jianxun Li
5抱歉,但我(以及可能其他人)不会从图像中转录您的输入数据并重建数据框。如果您需要帮助,那么您需要帮助我们,以便我们能够帮助您。 - EdChum
抱歉 @JianxunLi,我不明白你所说的“原始数据”是什么意思。
我的英语不是很好。 - issouluch
显示剩余9条评论
1个回答
11
在样本组中检验ARMA模型:
import pandas as pd
from pandas.tseries.offsets import *
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
csv_file = '/home/Jian/Downloads/analyse vtr.csv'
df = pd.read_csv(csv_file, index_col=[0], sep='\t')
grouped = df.groupby('adserver_id')
group = list(grouped)[0][1]
ts_data = pd.TimeSeries(group.c_start.values, index=pd.to_datetime(group.day))
# positive-valued process, looks non-stationary
# simple way is to do a log transform
fig, axes = plt.subplots(figsize=(10,8), nrows=3)
ts_data.plot(ax=axes[0])
ts_log_data = np.log(ts_data)
ts_log_data.plot(ax=axes[1], style='b-', label='actual')
# in-sample fit
# ===================================
model = sm.tsa.ARMA(ts_log_data, order=(1,1)).fit()
print(model.params)
y_pred = model.predict(ts_log_data.index[0].isoformat(), ts_log_data.index[-1].isoformat())
y_pred.plot(ax=axes[1], style='r--', label='in-sample fit')
y_resid = model.resid
y_resid.plot(ax=axes[2])
# out-sample predict
# ===================================
start_date = ts_log_data.index[-1] + Day(1)
end_date = ts_log_data.index[-1] + Day(7)
y_forecast = model.predict(start_date.isoformat(), end_date.isoformat())
print(y_forecast)
2015-07-11 7.5526
2015-07-12 7.4584
2015-07-13 7.3830
2015-07-14 7.3224
2015-07-15 7.2739
2015-07-16 7.2349
2015-07-17 7.2037
Freq: D, dtype: float64
# NOTE: this step introduces bias, it is used here just for simplicity
# E[exp(x)] != exp[E[x]]
print(np.exp(y_forecast))
2015-07-11 1905.6328
2015-07-12 1734.4442
2015-07-13 1608.3362
2015-07-14 1513.8595
2015-07-15 1442.1183
2015-07-16 1387.0486
2015-07-17 1344.4080
Freq: D, dtype: float64
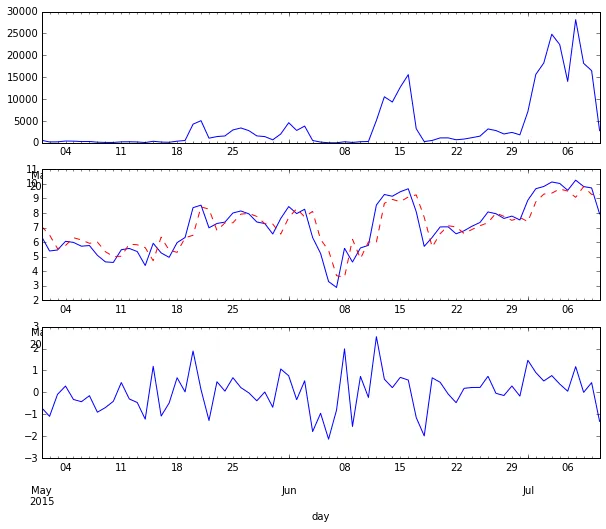
为每个子组运行ARMA模型(非常耗时):
import pandas as pd
from pandas.tseries.offsets import *
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
csv_file = '/home/Jian/Downloads/analyse vtr.csv'
df = pd.read_csv(csv_file, index_col=[0], sep='\t')
grouped = df.groupby('adserver_id')
def forecast_func(group):
ts_log_data = np.log(pd.TimeSeries(group.c_start.values, index=pd.to_datetime(group.day)))
# for some group, it raise convergence issue
try:
model = sm.tsa.ARMA(ts_log_data, order=(1,1)).fit()
start_date = ts_log_data.index[-1] + Day(1)
end_date = ts_log_data.index[-1] + Day(7)
y_forecast = model.predict(start_date.isoformat(), end_date.isoformat())
return pd.Series(np.exp(y_forecast).values, np.arange(1, 8))
except Exception:
pass
result = df.groupby('adserver_id').apply(forecast_func)
备选模型:为了快速计算,考虑使用指数平滑法;另外,我发现数据看起来像是一个具有时变泊松分布的正值过程,可以考虑使用pymc模块的状态空间模型。
- Jianxun Li
5
非常感谢您的帮助@JianxunLi。
它似乎工作得很好。
祝您有愉快的一天 :) - issouluch
@issouluch 非常欢迎你。很高兴能帮到你。 - Jianxun Li
当然有帮助!你知道ARMA方法中的“order”(sm.tsa.ARMA(ts_log_data,order =(1,1)))是什么意思吗?我该如何更改它以获得其他结果? - issouluch
嗨,我正在尝试在我的数据集上运行以上代码。读取CSV文件时,列名被删除了。当我执行groupby时它会抛出KeyError。请告诉我,如何解决这个问题。 - Anagha
1模块“pandas”没有属性“TimeSeries” :( - kiradotee
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接