我正在尝试使用低秩逼近进行潜在语义索引。我认为进行低秩逼近会减少矩阵维数,但我的结果与此相反。
假设我有一个包含40,000个单词和2000个文档的字典。那么,我的按项排序的文档矩阵是40,000 x 2000。根据维基百科的说法,我需要对矩阵进行SVD,然后应用
结果矩阵为:(40 000 x 20) * (20 x 20) * (20, 2000) = 40 000 x 2000,这恰好是我最初的矩阵。那么,低秩逼近如何准确地降低矩阵的维度呢?此外,我将对这个近似矩阵进行查询,以找到用户向量和每个文档之间的相关性(朴素搜索引擎)。 用户向量最初具有 40 000 x 1 的维度(词袋模型)。根据同一维基百科页面,我应该这样做:
假设我有一个包含40,000个单词和2000个文档的字典。那么,我的按项排序的文档矩阵是40,000 x 2000。根据维基百科的说法,我需要对矩阵进行SVD,然后应用
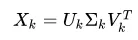
import scipy
import numpy as np
u, s, vt = scipy.sparse.linalg.svds(search_matrix, k=20)
search_matrix = u @ np.diag(s) @ vt
print('u: ', u.shape) # (40000, 20)
print('s: ', s.shape) # (20, )
print('vt: ', vt.shape) # (20, 2000)
结果矩阵为:(40 000 x 20) * (20 x 20) * (20, 2000) = 40 000 x 2000,这恰好是我最初的矩阵。那么,低秩逼近如何准确地降低矩阵的维度呢?此外,我将对这个近似矩阵进行查询,以找到用户向量和每个文档之间的相关性(朴素搜索引擎)。 用户向量最初具有 40 000 x 1 的维度(词袋模型)。根据同一维基百科页面,我应该这样做:
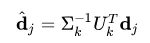
代码:
user_vec = np.diag((1 / s)) @ u.T @ user_vec
这个程序生成了一个 20 x 1 的矩阵,这正是我所期望的!((20 x 20) * (20 x 40,000) * (40,000 x 1) = (20 x 1))。但现在,它的维度与我想要乘以的搜索矩阵不匹配。
那么... 我做错了什么,为什么会这样?
来源: